Tim Retout: Prevent DOM-XSS with Trusted Types - a smarter DevSecOps approach
It can be incredibly easy for a frontend developer to accidentally
write a client-side cross-site-scripting (DOM-XSS) security issue, and
yet these are hard for security teams to detect. Vulnerability
scanners are slow, and suffer from false positives. Can smarter
collaboration between development, operations and security teams
provide a way to eliminate these problems altogether?
Google claims that Trusted
Types has all but eliminated
DOM-XSS exploits on those of their sites which have implemented
it. Let s find out how this can work!
DOM-XSS vulnerabilities are easy to write, but hard for security teams to catch
It is very easy to accidentally introduce a client-side XSS problem.
As an example of what not to do, suppose you are setting an element s
text to the current URL, on the client side:
DOM-XSS vulnerabilities are easy to write, but hard for security teams to catch
It is very easy to accidentally introduce a client-side XSS problem.
As an example of what not to do, suppose you are setting an element s
text to the current URL, on the client side:
// Don't do this
para.innerHTML = location.href;
Unfortunately, an attacker can now manipulate the URL (and e.g. send
this link in a phishing email), and any HTML tags they add will be
interpreted by the user s browser. This could potentially be used by
the attacker to send private data to a different server.
Detecting DOM-XSS using vulnerability scanning tools is challenging -
typically this requires crawling each page of the website and
attempting to detect problems such as the one above, but there is a
significant risk of false positives, especially as the complexity of
the logic increases.
There are already ways to avoid these exploits developers
should validate untrusted input before making use of it. There are
libraries such as DOMPurify
which can help with sanitization.1
However, if you are part of a security team with responsibility for
preventing these issues, it can be complex to understand whether you
are at risk. Different developer teams may be using different
techniques and tools. It may be impossible for you to work closely
with every developer so how can you know that the frontend
team have used these libraries correctly?
Trusted Types closes the DevSecOps feedback loop for DOM-XSS, by allowing Ops and Security to verify good Developer practices
Trusted Types enforces sanitization in the browser2, by requiring
the web developer to assign a particular kind of JavaScript object
rather than a native string to .innerHTML and other dangerous
properties. Provided these special types are created in an
appropriate way, then they can be trusted not to expose XSS
problems.
This approach will work with whichever tools the frontend developers have
chosen to use, and detection of issues can be rolled out by
infrastructure engineers without requiring frontend code changes.
Content Security Policy allows enforcement of security policies in the browser itself
Because enforcing this safer approach in the browser for all websites
would break backwards-compatibility, each website must opt-in through
Content Security Policy headers.
Content Security Policy (CSP) is a mechanism that allows web pages
to restrict what actions a browser should execute on their page, and a
way for the site to receive reports if the policy is violated.
 Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
Trusted Types can be rolled out incrementally, with continuous feedback
Web.dev s article on Trusted Types
explains how to safely roll out the feature using the features of CSP itself:
- Deploy a CSP collector if you haven t already
- Switch on CSP reports without enforcement (via
Content-Security-Policy-Report-Only headers)
- Iteratively review and fix the violations
- Switch to enforcing mode when there are a low enough rate of reports
Static analysis in a continuous integration pipeline is also sensible
you want to prevent regressions shipping in new releases
before they trigger a flood of CSP reports. This will also give you a
chance of finding any low-traffic vulnerable pages.
Smart security teams will use techniques like Trusted Types to eliminate entire classes of bugs at a time
Rather than playing whack-a-mole with unreliable vulnerability
scanning or bug bounties, techniques such as Trusted Types are truly
in the spirit of Secure by Design build high quality in from
the start of the engineering process, and do this in a way which
closes the DevSecOps feedback loop between your Developer, Operations
and Security teams.
-
Sanitization libraries are especially needed when the examples
become more complex, e.g. if the application must manipulate the
input. DOMPurify version 1.0.9 also added Trusted Types support, so
can still be used to help developers adopt this feature.
-
Trusted Types has existed in Chrome and Edge since 2020, and
should soon be coming to
Firefox
as well. However, it s not necessary to wait for Firefox or Safari to
add support, because the large market share of Chrome and Edge will
let you identify and fix your site s DOM-XSS issues, even if you do
not set enforcing mode, and users of all browsers will benefit. Even
so, it is great that Mozilla is now on board.
// Don't do this
para.innerHTML = location.href;
.innerHTML and other dangerous
properties. Provided these special types are created in an
appropriate way, then they can be trusted not to expose XSS
problems.
This approach will work with whichever tools the frontend developers have
chosen to use, and detection of issues can be rolled out by
infrastructure engineers without requiring frontend code changes.
Content Security Policy allows enforcement of security policies in the browser itself
Because enforcing this safer approach in the browser for all websites
would break backwards-compatibility, each website must opt-in through
Content Security Policy headers.
Content Security Policy (CSP) is a mechanism that allows web pages
to restrict what actions a browser should execute on their page, and a
way for the site to receive reports if the policy is violated.
Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
Trusted Types can be rolled out incrementally, with continuous feedback
Web.dev s article on Trusted Types
explains how to safely roll out the feature using the features of CSP itself:
- Deploy a CSP collector if you haven t already
- Switch on CSP reports without enforcement (via
Content-Security-Policy-Report-Only headers)
- Iteratively review and fix the violations
- Switch to enforcing mode when there are a low enough rate of reports
Static analysis in a continuous integration pipeline is also sensible
you want to prevent regressions shipping in new releases
before they trigger a flood of CSP reports. This will also give you a
chance of finding any low-traffic vulnerable pages.
Smart security teams will use techniques like Trusted Types to eliminate entire classes of bugs at a time
Rather than playing whack-a-mole with unreliable vulnerability
scanning or bug bounties, techniques such as Trusted Types are truly
in the spirit of Secure by Design build high quality in from
the start of the engineering process, and do this in a way which
closes the DevSecOps feedback loop between your Developer, Operations
and Security teams.
-
Sanitization libraries are especially needed when the examples
become more complex, e.g. if the application must manipulate the
input. DOMPurify version 1.0.9 also added Trusted Types support, so
can still be used to help developers adopt this feature.
-
Trusted Types has existed in Chrome and Edge since 2020, and
should soon be coming to
Firefox
as well. However, it s not necessary to wait for Firefox or Safari to
add support, because the large market share of Chrome and Edge will
let you identify and fix your site s DOM-XSS issues, even if you do
not set enforcing mode, and users of all browsers will benefit. Even
so, it is great that Mozilla is now on board.
- Deploy a CSP collector if you haven t already
- Switch on CSP reports without enforcement (via
Content-Security-Policy-Report-Onlyheaders) - Iteratively review and fix the violations
- Switch to enforcing mode when there are a low enough rate of reports
Smart security teams will use techniques like Trusted Types to eliminate entire classes of bugs at a time
Rather than playing whack-a-mole with unreliable vulnerability
scanning or bug bounties, techniques such as Trusted Types are truly
in the spirit of Secure by Design build high quality in from
the start of the engineering process, and do this in a way which
closes the DevSecOps feedback loop between your Developer, Operations
and Security teams.
-
Sanitization libraries are especially needed when the examples
become more complex, e.g. if the application must manipulate the
input. DOMPurify version 1.0.9 also added Trusted Types support, so
can still be used to help developers adopt this feature.
-
Trusted Types has existed in Chrome and Edge since 2020, and
should soon be coming to
Firefox
as well. However, it s not necessary to wait for Firefox or Safari to
add support, because the large market share of Chrome and Edge will
let you identify and fix your site s DOM-XSS issues, even if you do
not set enforcing mode, and users of all browsers will benefit. Even
so, it is great that Mozilla is now on board.
- Sanitization libraries are especially needed when the examples become more complex, e.g. if the application must manipulate the input. DOMPurify version 1.0.9 also added Trusted Types support, so can still be used to help developers adopt this feature.
- Trusted Types has existed in Chrome and Edge since 2020, and should soon be coming to Firefox as well. However, it s not necessary to wait for Firefox or Safari to add support, because the large market share of Chrome and Edge will let you identify and fix your site s DOM-XSS issues, even if you do not set enforcing mode, and users of all browsers will benefit. Even so, it is great that Mozilla is now on board.








 You can see how trees represent directories, blobs represent files, and so
on. Git can avoid internal duplication of files or directories which remain
identical. The hash function allows very efficient lookup of each object
within git s on-disk storage.
Tag and commit signatures do not directly sign the files in the repository;
that is, the input to the signature function is the content of the tag/commit
object, rather than the files themselves. This is analogous to the way that
GPG signatures actually sign a cryptographic hash of your email, and there
was a time when this too defaulted to SHA-1. An attacker who can break that
hash function can bypass the guarantees of the signature function.
A motivated attacker might be able to replace a blob, commit or tree in a git
repository using a SHA-1 collision. Replacing a blob seems easier to me than a
commit or tree, because there is no requirement that the content of the files
must conform to any particular format.
There is one key technical mitigation to this in Git, which is the
You can see how trees represent directories, blobs represent files, and so
on. Git can avoid internal duplication of files or directories which remain
identical. The hash function allows very efficient lookup of each object
within git s on-disk storage.
Tag and commit signatures do not directly sign the files in the repository;
that is, the input to the signature function is the content of the tag/commit
object, rather than the files themselves. This is analogous to the way that
GPG signatures actually sign a cryptographic hash of your email, and there
was a time when this too defaulted to SHA-1. An attacker who can break that
hash function can bypass the guarantees of the signature function.
A motivated attacker might be able to replace a blob, commit or tree in a git
repository using a SHA-1 collision. Replacing a blob seems easier to me than a
commit or tree, because there is no requirement that the content of the files
must conform to any particular format.
There is one key technical mitigation to this in Git, which is the 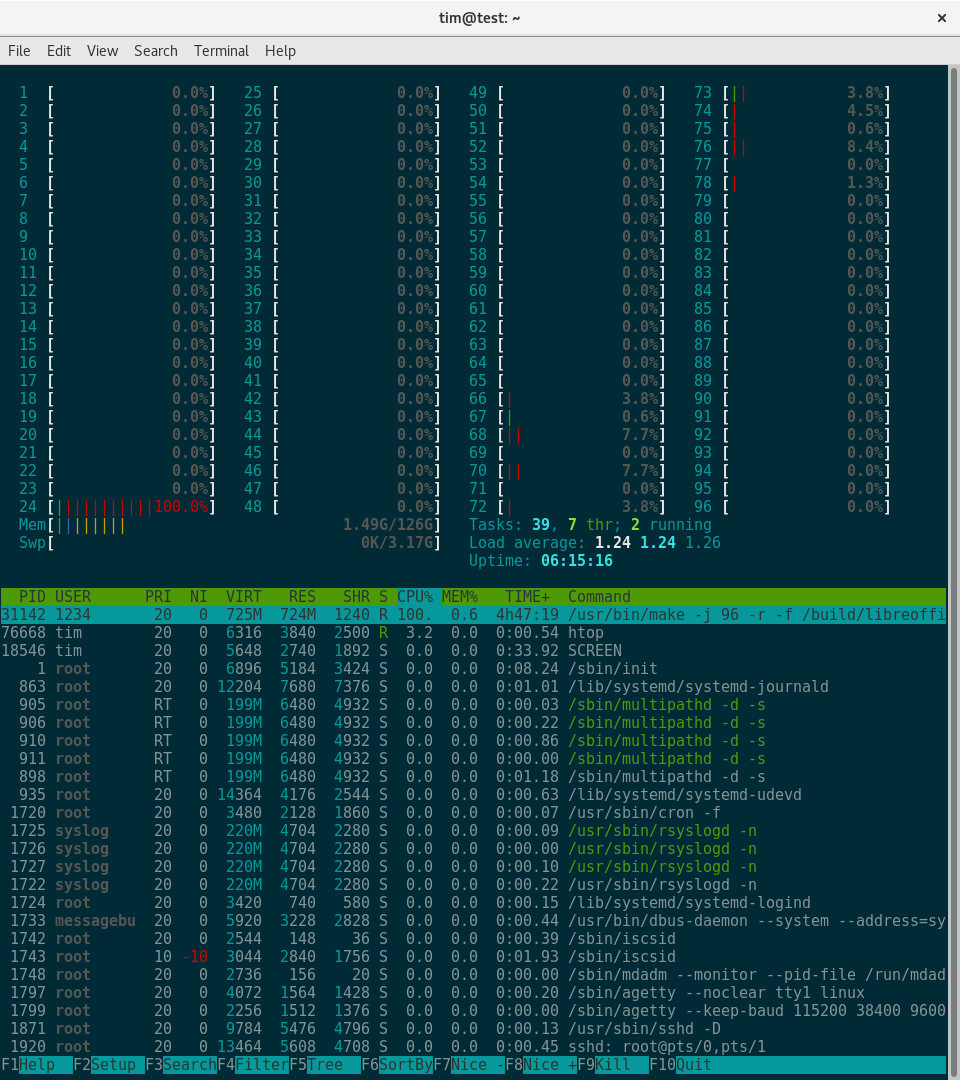 Final build time: around 12 hours, compared to 2hr 55m on the official arm64 buildd.
Most of the Libreoffice build appeared to consist of "touch /some/file"
repeated endlessly - I have a suspicion that the I/O performance might be low
on this server (although I have no further evidence to offer for this). I
think the next thing to try is building on a tmpfs, because the server has
128GB RAM available, and it's a shame not to use it.
Final build time: around 12 hours, compared to 2hr 55m on the official arm64 buildd.
Most of the Libreoffice build appeared to consist of "touch /some/file"
repeated endlessly - I have a suspicion that the I/O performance might be low
on this server (although I have no further evidence to offer for this). I
think the next thing to try is building on a tmpfs, because the server has
128GB RAM available, and it's a shame not to use it.