Russell Coker: Links September 2021
Matthew Garrett wrote an interesting and insightful blog post about the license of software developed or co-developed by machine-learning systems [1]. One of his main points is that people in the FOSS community should aim for less copyright protection.
The USENIX ATC 21/OSDI 21 Joint Keynote Address titled It s Time for Operating Systems to Rediscover Hardware has some inssightful points to make [2]. Timothy Roscoe makes some incendiaty points but backs them up with evidence. Is Linux really an OS? I recommend that everyone who s interested in OS design watch this lecture.
Cory Doctorow wrote an interesting set of 6 articles about Disneyland, ride pricing, and crowd control [3]. He proposes some interesting ideas for reforming Disneyland.
Benjamin Bratton wrote an insightful article about how philosophy failed in the pandemic [4]. He focuses on the Italian philosopher Giorgio Agamben who has a history of writing stupid articles that match Qanon talking points but with better language skills.
Arstechnica has an interesting article about penetration testers extracting an encryption key from the bus used by the TPM on a laptop [5]. It s not a likely attack in the real world as most networks can be broken more easily by other methods. But it s still interesting to learn about how the technology works.
The Portalist has an article about David Brin s Startide Rising series of novels and his thought s on the concept of Uplift (which he denies inventing) [6].
Jacobin has an insightful article titled You re Not Lazy But Your Boss Wants You to Think You Are [7]. Making people identify as lazy is bad for them and bad for getting them to do work. But this is the first time I ve seen it described as a facet of abusive capitalism.
Jacobin has an insightful article about free public transport [8]. Apparently there are already many regions that have free public transport (Tallinn the Capital of Estonia being one example). Fare free public transport allows bus drivers to concentrate on driving not taking fares, removes the need for ticket inspectors, and generally provides a better service. It allows passengers to board buses and trams faster thus reducing traffic congestion and encourages more people to use public transport instead of driving and reduces road maintenance costs.
Interesting research from Israel about bypassing facial ID [9]. Apparently they can make a set of 9 images that can pass for over 40% of the population. I didn t expect facial recognition to be an effective form of authentication, but I didn t expect it to be that bad.
Edward Snowden wrote an insightful blog post about types of conspiracies [10].
Kevin Rudd wrote an informative article about Sky News in Australia [11]. We need to have a Royal Commission now before we have our own 6th Jan event.
Steve from Big Mess O Wires wrote an informative blog post about USB-C and 4K 60Hz video [12]. Basically you can t have a single USB-C hub do 4K 60Hz video and be a USB 3.x hub unless you have compression software running on your PC (slow and only works on Windows), or have DisplayPort 1.4 or Thunderbolt (both not well supported). All of the options are not well documented on online store pages so lots of people will get unpleasant surprises when their deliveries arrive. Computers suck.
Steinar H. Gunderson wrote an informative blog post about GaN technology for smaller power supplies [13]. A 65W USB-C PSU that fits the usual wall wart form factor is an interesting development.
- [1] https://mjg59.dreamwidth.org/57615.html
- [2] https://www.youtube.com/watch?v=36myc8wQhLo
- [3] https://tinyurl.com/yzo22rub
- [4] https://tinyurl.com/yf3q8p4y
- [5] https://tinyurl.com/ydr79yqf
- [6] https://theportalist.com/david-brin-startide-rising-introduction-uplift
- [7] https://www.jacobinmag.com/2021/02/laziness-work-capitalism-review-devon-price
- [8] https://www.jacobinmag.com/2018/08/public-transportation-brussels-free-tickets
- [9] https://tinyurl.com/yek4p8sv
- [10] https://edwardsnowden.substack.com/p/conspiracy-pt1
- [11] https://tinyurl.com/yh88rj5u
- [12] https://tinyurl.com/y6on8jcd
- [13] https://tinyurl.com/yegot6qv
 Narabu is a new intraframe video codec. You probably want to read
Narabu is a new intraframe video codec. You probably want to read
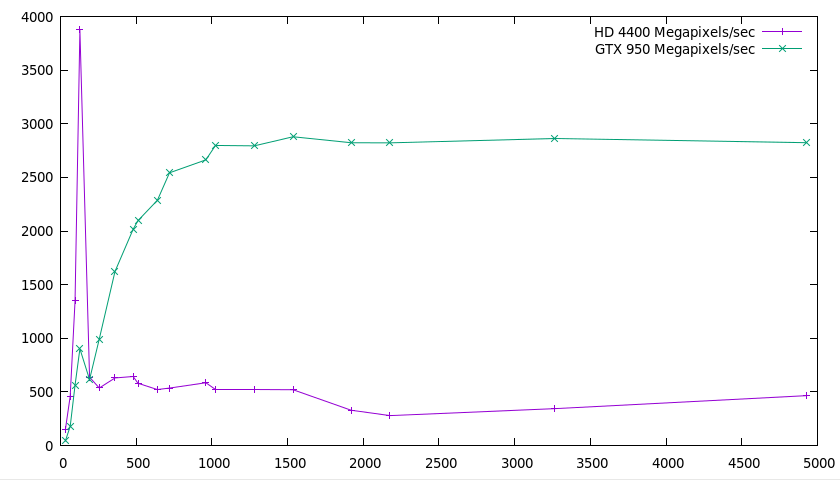 I'm not going to comment much beyond two observations:
I'm not going to comment much beyond two observations:
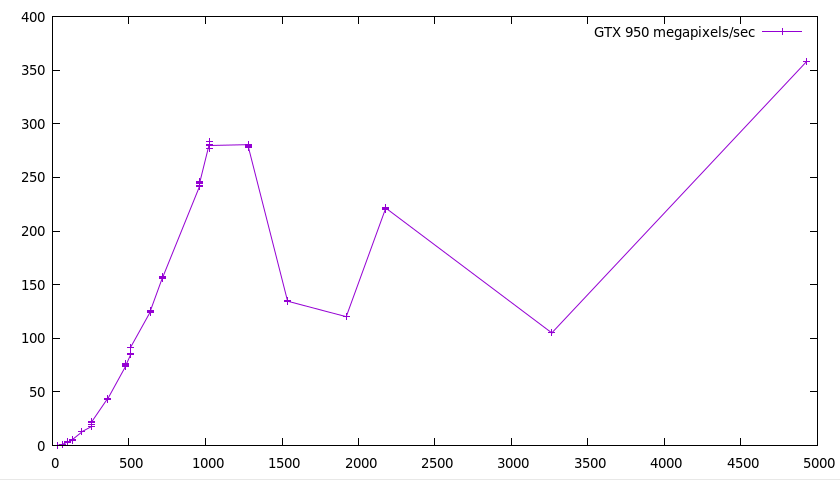 This is interesting. I have few explanations. Probably more benchmarking and
profiling would be needed to make sense of any of it. In fact, it's so
strange that I would suspect a bug, but it does indeed seem to create a
valid bitstream that is decoded by the decoder.
Do note, however, that seemingly even on the smallest resolutions, there's a
1.7 ms base cost (you can't see it on the picture, but you'd see it in an
unnormalized graph). I don't have a very good explanation for this either
(even though there are some costs that are dependent on the alphabet size
instead of the number of pixels), but figuring it out would probably be a
great start for getting the performance up.
So that concludes the series, on a cliffhanger. :-) Even though it's not in a
situation where you can just take it and put it into something useful, I hope
it was an interesting introduction to the GPU! And in the meantime, I've
released version 1.6.3 of
This is interesting. I have few explanations. Probably more benchmarking and
profiling would be needed to make sense of any of it. In fact, it's so
strange that I would suspect a bug, but it does indeed seem to create a
valid bitstream that is decoded by the decoder.
Do note, however, that seemingly even on the smallest resolutions, there's a
1.7 ms base cost (you can't see it on the picture, but you'd see it in an
unnormalized graph). I don't have a very good explanation for this either
(even though there are some costs that are dependent on the alphabet size
instead of the number of pixels), but figuring it out would probably be a
great start for getting the performance up.
So that concludes the series, on a cliffhanger. :-) Even though it's not in a
situation where you can just take it and put it into something useful, I hope
it was an interesting introduction to the GPU! And in the meantime, I've
released version 1.6.3 of 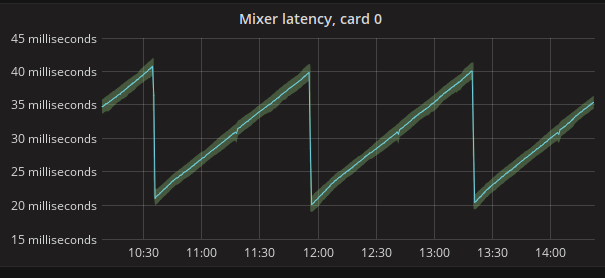 As you can see, the latency goes up, up, up until Nageru figures it's now
safe to drop a frame, and then does it in one clean drop event; no more
hundreds on drops involved. There are very late frame arrivals involved in
this run two extra frame drops, to be precise but the algorithm simply
determines immediately that they are outliers, and drops them without letting
them linger in the queue. (Immediate dropping is usually preferred to
sticking around for a bit and then dropping it later, as it means you only
get one disturbance event in your stream as opposed to two. Of course, you
can only do it if you're reasonably sure it won't lead to more underruns
later.)
Nageru 1.6.1 will ship before
As you can see, the latency goes up, up, up until Nageru figures it's now
safe to drop a frame, and then does it in one clean drop event; no more
hundreds on drops involved. There are very late frame arrivals involved in
this run two extra frame drops, to be precise but the algorithm simply
determines immediately that they are outliers, and drops them without letting
them linger in the queue. (Immediate dropping is usually preferred to
sticking around for a bit and then dropping it later, as it means you only
get one disturbance event in your stream as opposed to two. Of course, you
can only do it if you're reasonably sure it won't lead to more underruns
later.)
Nageru 1.6.1 will ship before 
 There are also corresponding SDI-to-HDMI converters that look pretty much
the same except they convert the other way. (They're easy to confuse, but
that's not a problem unique tothem.)
I've used them for a while now, and there are pros and cons. They seem
reliable enough, and they're 1/4th the price of e.g. Blackmagic's Micro
converters, which is a real bargain. However, there are also some issues:
There are also corresponding SDI-to-HDMI converters that look pretty much
the same except they convert the other way. (They're easy to confuse, but
that's not a problem unique tothem.)
I've used them for a while now, and there are pros and cons. They seem
reliable enough, and they're 1/4th the price of e.g. Blackmagic's Micro
converters, which is a real bargain. However, there are also some issues: