Soeren Sonnenburg: Shogun Toolbox Version 3.0 released!
Dear all,
we are proud to announce the 3.0 release of the Shogun Machine-Learning Toolbox. This release features the incredible projects of our 8 hard-working Google Summer of Code students. In addition, you get other cool new features as well as lots of internal improvements, bugfixes, and documentation improvements. To speak in numbers, we got more than 2000 commits changing almost 400000 lines in more than 7000 files and increased the number of unit tests from 50 to 600. This is the largest release that Shogun ever had! Please visit http://shogun-toolbox.org/ to obtain Shogun.
News
Here is a brief description of what is new, starting with the GSoC projects, which deserve most fame:
![FGM.html]()
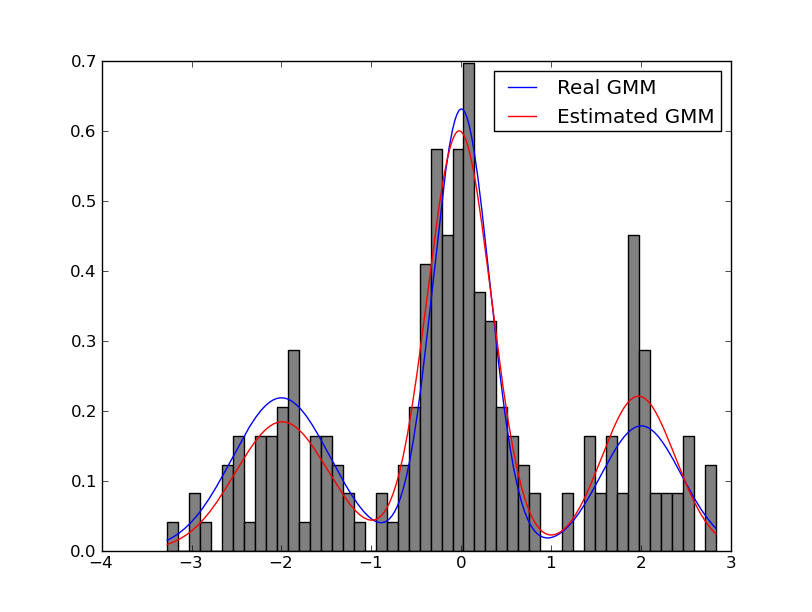
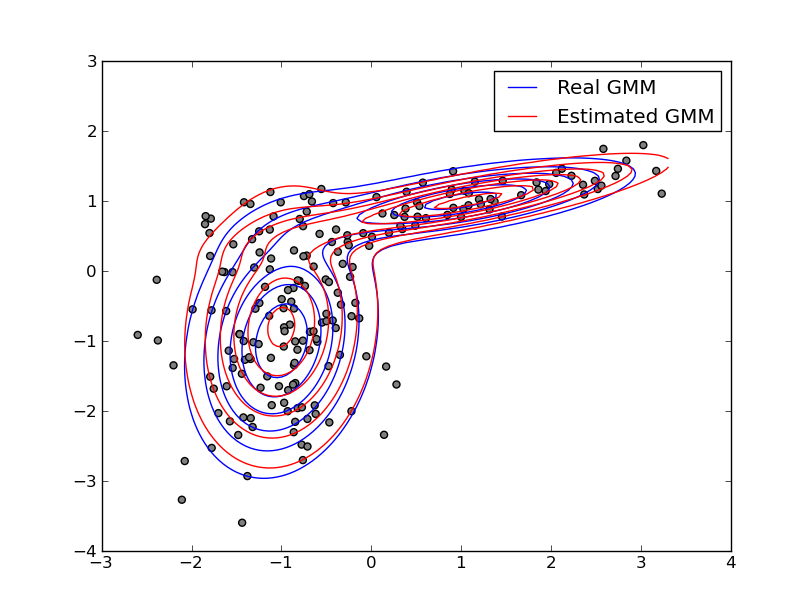
![GMM.html]()
![HashedDocDotFeatures.html]()
![LMNN.html]()
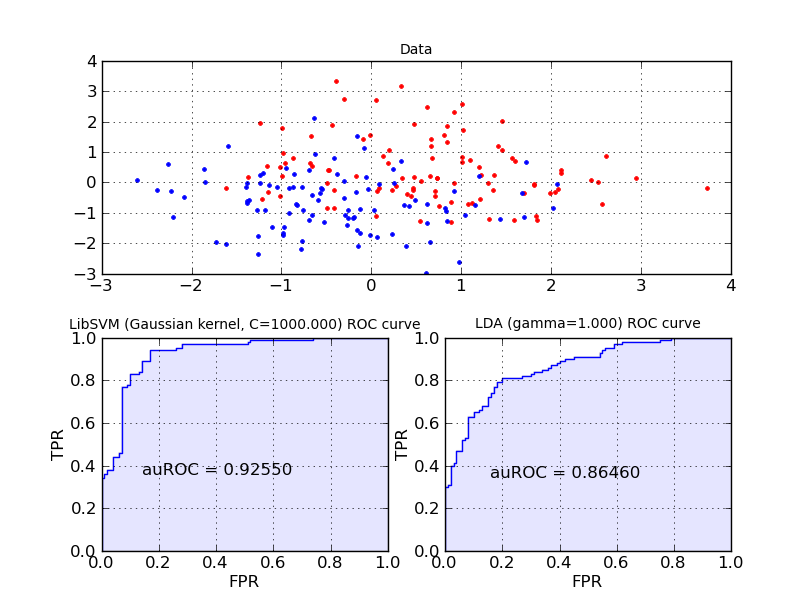
![SupportVectorMachines.html]()
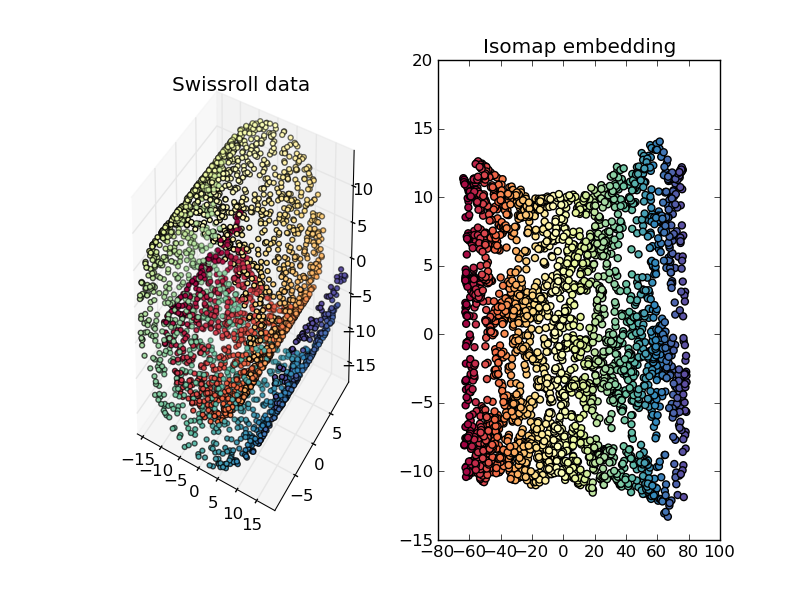
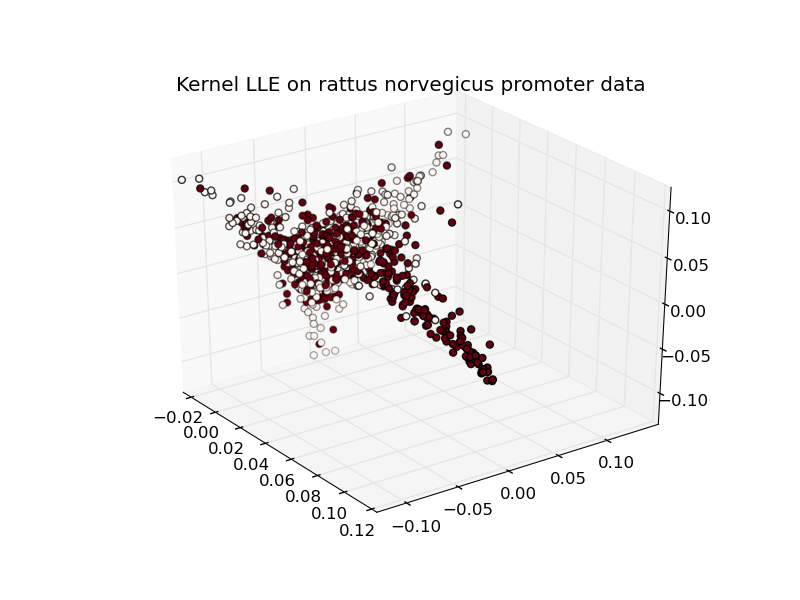
![Tapkee.html]()
![bss_audio.html]()
![bss_image.html]()
![ecg_sep.html]()
![gaussian_processes.html]()
![logdet.html]()
![mmd_two_sample_testing.html]() The web-demo framework has been integrated into our website, go check them out.
The web-demo framework has been integrated into our website, go check them out.









 Other changes
We finally moved to the Shogun build process to CMake.
Through GSoC, added a general clone and equals methods to all Shogun objects, and added automagic
unit-testing for serialisation and clone/equals for all classes. Other new features include
multiclass LDA, and probability outputs for multiclass SVMs. For the full list, see the NEWS.
Workshop Videos and slides
In case you missed the first Shogun workshop that we organised in Berlin last July, all of the talks have been put online.
Shogun in the Cloud
As setting up the right environment for shogun and installing it was always one of the biggest problems for the users (hence the switching to CMake), we have created a sandbox where you can try out shogun on your own without installing shogun on your system! Basically it's a web-service which give you access to your own ipython notebook server with all the shogun notebooks.
Of course you are more than welcome to create and share your own notebooks using this service!
*NOTE*: This is a courtesy service created by Shogun Toolbox developers, hence if you like it please
consider some form of donation to the project so that we can keep up this service running for you.
Try shogun in the cloud.
Thanks
The release has been made possible by the hard work of all of our GSoC students, see list above. Thanks also to Thoralf Klein and Bj rn Esser for the load of great contributions. Last but not least, thanks to all the people who use Shogun and provide feedback.
S ren Sonnenburg on behalf of the Shogun team
(+ Viktor Gal, Sergey Lisitsyn, Heiko Strathmann and Fernando Iglesias)
Other changes
We finally moved to the Shogun build process to CMake.
Through GSoC, added a general clone and equals methods to all Shogun objects, and added automagic
unit-testing for serialisation and clone/equals for all classes. Other new features include
multiclass LDA, and probability outputs for multiclass SVMs. For the full list, see the NEWS.
Workshop Videos and slides
In case you missed the first Shogun workshop that we organised in Berlin last July, all of the talks have been put online.
Shogun in the Cloud
As setting up the right environment for shogun and installing it was always one of the biggest problems for the users (hence the switching to CMake), we have created a sandbox where you can try out shogun on your own without installing shogun on your system! Basically it's a web-service which give you access to your own ipython notebook server with all the shogun notebooks.
Of course you are more than welcome to create and share your own notebooks using this service!
*NOTE*: This is a courtesy service created by Shogun Toolbox developers, hence if you like it please
consider some form of donation to the project so that we can keep up this service running for you.
Try shogun in the cloud.
Thanks
The release has been made possible by the hard work of all of our GSoC students, see list above. Thanks also to Thoralf Klein and Bj rn Esser for the load of great contributions. Last but not least, thanks to all the people who use Shogun and provide feedback.
S ren Sonnenburg on behalf of the Shogun team
(+ Viktor Gal, Sergey Lisitsyn, Heiko Strathmann and Fernando Iglesias)
- Gaussian Process classification by Roman Votjakov
- Structured Output Learning of graph models by Shell Hu
- Estimators for log-determinants of large sparse matrices by Soumyajit De
- Feature Hashing and random kitchen sinks by Evangelos Anagnostopoulos
- Independent Component Analysis by Kevin Hughes
- A web-based demo framework by Liu Zhengyang
- Metric learning with large margin nearest neighbours by Fernando Iglesias
- Native support for various popular file formats by Evgeniy Andreev
Other changes
We finally moved to the Shogun build process to CMake.
Through GSoC, added a general clone and equals methods to all Shogun objects, and added automagic
unit-testing for serialisation and clone/equals for all classes. Other new features include
multiclass LDA, and probability outputs for multiclass SVMs. For the full list, see the NEWS.
Workshop Videos and slides
In case you missed the first Shogun workshop that we organised in Berlin last July, all of the talks have been put online.
Shogun in the Cloud
As setting up the right environment for shogun and installing it was always one of the biggest problems for the users (hence the switching to CMake), we have created a sandbox where you can try out shogun on your own without installing shogun on your system! Basically it's a web-service which give you access to your own ipython notebook server with all the shogun notebooks.
Of course you are more than welcome to create and share your own notebooks using this service!
*NOTE*: This is a courtesy service created by Shogun Toolbox developers, hence if you like it please
consider some form of donation to the project so that we can keep up this service running for you.
Try shogun in the cloud.
Thanks
The release has been made possible by the hard work of all of our GSoC students, see list above. Thanks also to Thoralf Klein and Bj rn Esser for the load of great contributions. Last but not least, thanks to all the people who use Shogun and provide feedback.
S ren Sonnenburg on behalf of the Shogun team
(+ Viktor Gal, Sergey Lisitsyn, Heiko Strathmann and Fernando Iglesias)
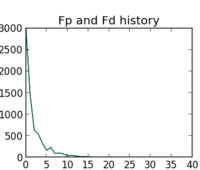
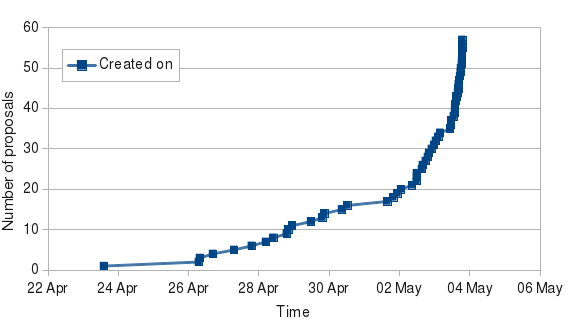 Comparing this to 2012, this curve is much more flat in the beginning but exponentially increasing towards the end. Why is that? We didn't change the way we engaged with students (even though we tried to improve the instructions and added lots of entrance tagged tasks to
Comparing this to 2012, this curve is much more flat in the beginning but exponentially increasing towards the end. Why is that? We didn't change the way we engaged with students (even though we tried to improve the instructions and added lots of entrance tagged tasks to 
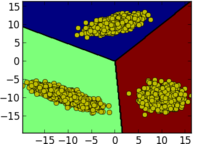
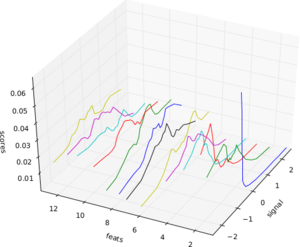 [1]
[1] 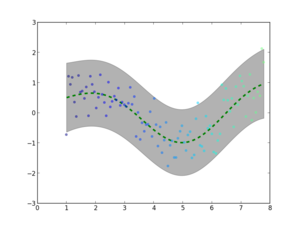
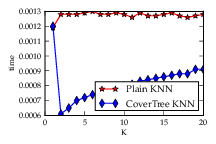
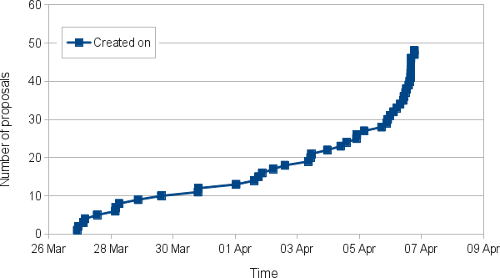 This is a drastic drop compared with last year (about 60 students submitted 70 proposals). However, this drop can easily be explained: To even apply we required a small patch, which is a big hurdle.
This is a drastic drop compared with last year (about 60 students submitted 70 proposals). However, this drop can easily be explained: To even apply we required a small patch, which is a big hurdle.

.png)