I needed to migrate an existing system to an Hetzner cloud VPS. While it is
possible to attach KVM consoles and custom ISO images to dedicated servers, i
didn t find any way to do so with regular cloud instances.
For system migrations i usually use REAR,
which has never failed me. (and also has saved my ass during recovery multiple
times). It s an awesome utility!
It s possible to do this using the Hetzner recovery console too, but using REAR
is very convenient here, because it handles things like re-creating the
partition layout and network settings automatically!
The steps are:
Create bootable REAR rescue image on the source system.
Register a target system in Hetzner Cloud with at least the same disk size as the source system.
Boot the REAR image s initrd and kernel from the running VPS system using kexec
Make the REAR recovery console accessible via SSH (or use Hetzners console).
Let REAR do its magic and re-partition the system.
Restore the system data to the freshly partitioned disks
Let REAR handle the bootloader and network re-configuration.
Example
To create a rescue image on the source system:
apt install rear
echo OUTPUT=ISO > /etc/rear/local.conf
rear mkrescue -v[..]
Wrote ISO image: /var/lib/rear/output/rear-debian12.iso (185M)
My source system had a 128 GB disk, so i registered an instance on Hetzner
cloud with greater disk size to make things easier:
Now copy the ISO image to the newly created instance and extract
its data:
Note down the current gateway configuration, this is required later
on to make the REAR recovery console reachable via SSH:
root@testme:~# ip route
default via 172.31.1.1 dev eth0
172.31.1.1 dev eth0 scope link
Reboot the running VPS instance into the REAR recovery image using somewhat
the same kernel cmdline:
root@testme:~# cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-6.1.0-13-amd64 root=UUID=5174a81e-5897-47ca-8fe4-9cd19dc678c4 ro consoleblank=0 systemd.show_status=true console=tty1 console=ttyS0
kexec --initrd /tmp/initrd.cgz --command-line="consoleblank=0 systemd.show_status=true console=tty1 console=ttyS0" /tmp/kernel
Connection to 49.13.193.226 closed by remote host.
Connection to 49.13.193.226 closed
Now watch the system on the Console booting into the REAR system:
Login the recovery console (root without password) and fix its default route to
make it reachable:
ip addr
[..]
2: enp1s0
..
$ ip route add 172.31.1.1 dev enp1s0
$ ip route add default via 172.31.1.1
ping 49.13.193.226
64 bytes from 49.13.193.226: icmp_seq=83 ttl=52 time=27.7 ms
The network configuration might differ, the source system in this example used
DHCP, as the target does. If REAR detects changed static network configuration
it guides you through the setup pretty nicely.
Login via SSH (REAR will store your ssh public keys in the image) and start the
recovery process, follow the steps as suggested by REAR:
ssh -l root 49.13.193.226
Welcome to Relax-and-Recover. Run "rear recover" to restore your system !
RESCUE debian12:~ # rear recover
Relax-and-Recover 2.7 / Git
Running rear recover (PID 673 date 2024-01-04 19:20:22)
Using log file: /var/log/rear/rear-debian12.log
Running workflow recover within the ReaR rescue/recovery system
Will do driver migration (recreating initramfs/initrd)
Comparing disks
Device vda does not exist (manual configuration needed)
Switching to manual disk layout configuration (GiB sizes rounded down to integer)
/dev/vda had size 137438953472 (128 GiB) but it does no longer exist
/dev/sda was not used on the original system and has now 163842097152 (152 GiB)
Original disk /dev/vda does not exist (with same size)in the target system
Using /dev/sda (the only available of the disks)for recreating /dev/vda
Current disk mapping table (source=> target):
/dev/vda => /dev/sda
Confirm or edit the disk mapping
1) Confirm disk mapping and continue'rear recover'[..]
User confirmed recreated disk layout
[..]
This step re-recreates your original disk layout and mounts it to /mnt/local/
(this example uses a pretty lame layout, but usually REAR will handle things
like lvm/btrfs just nicely):
mount
/dev/sda3 on /mnt/local type ext4 (rw,relatime,errors=remount-ro)
/dev/sda1 on /mnt/local/boot type ext4 (rw,relatime)
Now clone your source systems data to /mnt/local/ with whatever utility you
like to use and exit the recovery step. After confirming everything went well,
REAR will setup the bootloader (and all other config details like fstab entries
and adjusted network configuration) for you as required:
rear> exit
Did you restore the backup to /mnt/local ? Are you ready to continue recovery ? yes
User confirmed restored files
Updated initramfs with new drivers for this system.
Skip installing GRUB Legacy boot loader because GRUB 2 is installed (grub-probe or grub2-probe exist).
Installing GRUB2 boot loader...
Determining where to install GRUB2 (no GRUB2_INSTALL_DEVICES specified)
Found possible boot disk /dev/sda - installing GRUB2 there
Finished 'recover'. The target system is mounted at '/mnt/local'.
Exiting rear recover (PID 7103) and its descendant processes ...
Running exit tasks
Now reboot the recovery console and watch it boot into your target
systems configuration:
Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
If you want to test upgrades on virtual machines (running on libvit/qemu/kvm)
these are usually the most common steps:
Clone the virtual machine and test the upgrade.
Create a snapshot beforehand, do an in-place upgrade and hope everything
works. If not, revert the snapshot..
Combine both methods
Use LVM or filesystem snapshots (snapper, etc)
As with recent versions, both libvirt and qemu have full support for dirty
bitmaps (so called checkpoints). These checkpoints, once existent, will track
changes to the block level layer and can be exported via NBD protocol.
Usually one can create these checkpoints using virsh checkpoint-create[-as],
with a proper xml description.
Using the pull based model, the following is possible:
Issue an backup-begin statement and freeze the virtual machines file
systems during this process (using qemu-agent) so you get an consistent
system state.
Create an qcow2 image with backing image option that points to the created
(readonly) NBD export via unix socket as overlay.
Use the created overlay image to boot up the instance and test the system
upgrade.
Do so while the virtual machine is operating without any downtime.
The overlay image will only use the disk space for the blocks changed during
upgrade: no need to create a full clone which may waste a lot of disk space.
In order to simplify the first step, its possible to use
virtnbdbackup for creating the
required consistent checkpoint and export its data using a unix domain socket.
Update: As alternative, ive just created a small utility called
vircpt to create and export checkpoints.
In my example im using a debian11 virtual machine with qemu guest agent
configured:
# virsh list --all
Id Name State
------------------------------------------
1 debian11_default running
Now let virtnbdbackup create an checkpoint, freeze the filesystems during
creation and tell libvirt to provide us with a usable NBD server listening on
an unix socket:
# virtnbdbackup -d debian11_default -o /tmp/foo -s
INFO lib common - printVersion [MainThread]: Version: 1.9.45 Arguments: ./virtnbdbackup -d debian11_default -o /tmp/foo -s[..]
INFO root virtnbdbackup - main [MainThread]: Local NBD Endpoint socket: [/var/tmp/virtnbdbackup.5727]
INFO root virtnbdbackup - startBackupJob [MainThread]: Starting backup job.
INFO fs fs - freeze [MainThread]: Freezed [2] filesystems.
INFO fs fs - thaw [MainThread]: Thawed [2] filesystems.
INFO root virtnbdbackup - main [MainThread]: Started backup job for debugging, exiting.
We can now use nbdinfo to display some information about the NBD export:
# nbdinfo "nbd+unix:///vda?socket=/var/tmp/virtnbdbackup.5727"
protocol: newstyle-fixed without TLS, using structured packets
export="vda":
export-size: 137438953472 (128G)
content:
DOS/MBR boot sector uri: nbd+unix:///vda?socket=/var/tmp/virtnbdbackup.5727
And create a backing image that we can use to test an in-place upgrade:
# qemu-img create -F raw -b nbd+unix:///vda?socket=/var/tmp/virtnbdbackup.5727 -f qcow2 upgrade.qcow2
Now we have various ways for booting the image:
Create another domain config in libvirt which points to this disk image,
boot.
Extract the current qemu command line for the the running domain using
virsh domxml-to-native qemu-argv --domain debian11_default and execute it
manually after adjusting required parameters.
Trust for everything to work out in the simplest way and simply boot up the
image via:
While running CI tests for a application that is implemented in C and Java,
some configuration scripts set the current timezone. The C implemented parts
catch the change just nicely, but the java related parts still report the
default image timezone.
A simple example:
importjava.util.*;importjava.text.*;classsimpleTestpublicstaticvoidmain(Stringargs[])Calendarcal=Calendar.getInstance();System.out.println("TIME ZONE :"+cal.getTimeZone().getDisplayName());
Result:
vagrant@vm:~$ sudo timedatectl set-timezone America/Aruba
vagrant@vm:~$ timedatectl
[..]
Time zone: America/Aruba (AST, -0400)[..]
vagrant@vm:~$ java test.java
TIME ZONE :Central European Standard Time
vagrant@vm:~$ ls-alh /etc/localtime
lrwxrwxrwx 1 root root 35 Jul 10 14:41 /etc/localtime -> ../usr/share/zoneinfo/America/Aruba
It appears the Java implementation uses /etc/timezone as source, not
/etc/localtime.
vagrant@vm:~$ echo America/Aruba sudo tee /etc/timezone
America/Aruba
vagrant@vm:~$ java test.java
TIME ZONE :Atlantic Standard Time
dpkg-reconfigure tzdata updates this file as well, so using timedatectl
only won t be enough (at least not on Debian based systems which run java based
applications.)
Just updated to bookworm. Only thing that gave me headaches was OpenVPN
refusing to accept the password/username combination specified via
auth-user-pass option..
Mystery was solved by adding providers legacy default to the
configuration file used.
Welcome to the April 2023 report from the Reproducible Builds project!
In these reports we outline the most important things that we have been up to over the past month. And, as always, if you are interested in contributing to the project, please visit our Contribute page on our website.
The absolute number may not be impressive, but what I hope is at least a useful contribution is that there actually is a number on how much of Trisquel is reproducible. Hopefully this will inspire others to help improve the actual metric.
Simon wrote another blog post this month on a new tool to ensure that updates to Linux distribution archive metadata (eg. via apt-get update) will only use files that have been recorded in a globally immutable and tamper-resistant ledger. A similar solution exists for Arch Linux (called pacman-bintrans) which was announced in August 2021 where an archive of all issued signatures is publically accessible.
Joachim Breitner wrote an in-depth blog post on a bootstrap-capable GHC, the primary compiler for the Haskell programming language. As a quick background to what this is trying to solve, in order to generate a fully trustworthy compile chain, trustworthy root binaries are needed and a popular approach to address this problem is called bootstrappable builds where the core idea is to address previously-circular build dependencies by creating a new dependency path using simpler prerequisite versions of software. Joachim takes an somewhat recursive approach to the problem for Haskell, leading to the inadvertently humourous question: Can I turn all of GHC into one module, and compile that?
Elsewhere in the world of bootstrapping, Janneke Nieuwenhuizen and Ludovic Court s wrote a blog post on the GNU Guix blog announcing The Full-Source Bootstrap, specifically:
[ ] the third reduction of the Guix bootstrap binaries has now been merged in the main branch of Guix! If you run guix pull today, you get a package graph of more than 22,000 nodes rooted in a 357-byte program something that had never been achieved, to our knowledge, since the birth of Unix.
The full-source bootstrap was once deemed impossible. Yet, here we are, building the foundations of a GNU/Linux distro entirely from source, a long way towards the ideal that the Guix project has been aiming for from the start.
There are still some daunting tasks ahead. For example, what about the Linux kernel? The good news is that the bootstrappable community has grown a lot, from two people six years ago there are now around 100 people in the #bootstrappable IRC channel.
Michael Ablassmeier created a script called pypidiff as they were looking for a way to track differences between packages published on PyPI. According to Micahel, pypidiff uses diffoscope to create reports on the published releases and automatically pushes them to a GitHub repository. This can be seen on the pypi-diff GitHub page (example).
Eleuther AI, a non-profit AI research group, recently unveiled Pythia, a collection of 16 Large Language Model (LLMs) trained on public data in the same order designed specifically to facilitate scientific research. According to a post on MarkTechPost:
Pythia is the only publicly available model suite that includes models that were trained on the same data in the same order [and] all the corresponding data and tools to download and replicate the exact training process are publicly released to facilitate further research.
These properties are intended to allow researchers to understand how gender bias (etc.) can affected by training data and model scale.
Back in February s report we reported on a series of changes to the Sphinx documentation generator that was initiated after attempts to get the alembic Debian package to build reproducibly. Although Chris Lamb was able to identify the source problem and provided a potential patch that might fix it, James Addison has taken the issue in hand, leading to a large amount of activity resulting in a proposed pull request that is waiting to be merged.
WireGuard is a popular Virtual Private Network (VPN) service that aims to be faster, simpler and leaner than other solutions to create secure connections between computing devices. According to a post on the WireGuard developer mailing list, the WireGuard Android app can now be built reproducibly so that its contents can be publicly verified. According to the post by Jason A. Donenfeld, the F-Droid project now does this verification by comparing their build of WireGuard to the build that the WireGuard project publishes. When they match, the new version becomes available. This is very positive news.
Author and public speaker, V. M. Brasseur published a sample chapter from her upcoming book on corporate open source strategy which is the topic of Software Bill of Materials (SBOM):
A software bill of materials (SBOM) is defined as a nested inventory for software, a list of ingredients that make up software components. When you receive a physical delivery of some sort, the bill of materials tells you what s inside the box. Similarly, when you use software created outside of your organisation, the SBOM tells you what s inside that software. The SBOM is a file that declares the software supply chain (SSC) for that specific piece of software. []
Several distributions noticed recent versions of the Linux Kernel are no longer reproducible because the BPF Type Format (BTF) metadata is not generated in a deterministic way. This was discussed on the #reproducible-builds IRC channel, but no solution appears to be in sight for now.
Chris Lamb attempted a number of ways to try and fix literal : .lead appearing in the page [][][], made all the Back to who is involved links italics [], and corrected the syntax of the _data/sponsors.yml file [].
Holger Levsen added his recent talk [], added Simon Josefsson, Mike Perry and Seth Schoen to the contributors page [][][], reworked the People page a little [] [], as well as fixed spelling of Arch Linux [].
Lastly, Mattia Rizzolo moved some old sponsors to a former section [] and Simon Josefsson added Trisquel GNU/Linux. []
Debian
Vagrant Cascadian reported on the Debian s build-essential package set, which was inspired by how close we are to making the Debian build-essential set reproducible and how important that set of packages are in general . Vagrant mentioned that: I have some progress, some hope, and I daresay, some fears . [ ]
Debian Developer Cyril Brulebois (kibi) filed a bug against snapshot.debian.org after they noticed that there are many missing dinstalls that is to say, the snapshot service is not capturing 100% of all of historical states of the Debian archive. This is relevant to reproducibility because without the availability historical versions, it is becomes impossible to repeat a build at a future date in order to correlate checksums. .
20 reviews of Debian packages were added, 21 were updated and 5 were removed this month adding to our knowledge about identified issues. Chris Lamb added a new build_path_in_line_annotations_added_by_ruby_ragel toolchain issue. [ ]
Mattia Rizzolo announced that the data for the stretch archive on tests.reproducible-builds.orghas been archived. This matches the archival of stretch within Debian itself. This is of some historical interest, as stretch was the first Debian release regularly tested by the Reproducible Builds project.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In April, a number of changes were made, including:
Holger Levsen:
Significant work on a new Documented Jenkins Maintenance (djm) script to support logged maintenance of nodes, etc. [][][][][][]
Add the new APT repo url for Jenkins itself with a new signing key. [][]
In the Jenkins shell monitor, allow 40 GiB of files for diffoscope for the Debian experimental distribution as Debian is frozen around the release at the moment. []
Updated Arch Linux testing to cleanup leftover files left in /tmp/archlinux-ci/ after three days. [][][]
Introduce the archived suites configuration option. []][]
Fix the KGB bot configuration to support pyyaml 6.0 as present in Debian bookworm. []
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
I wondered if there is some tracking for differences between packages
published on pypi, something that stores this information in a format
similar to debdiff..
I failed to find something on the web, so created a little utility which
watches the pypi
changelog for new
releaes and fetches the new and old version.
It uses diffoscope to create reports on the published releases and
automatically pushes them to a github repository:
https://github.com/pypi-diff
Is it useful? I dont know, it may be handy for code review or maybe running
different security scanners on it, to identify accidentaly pushed keys or other
sensitive data.
Currently its pushing the changes for every released package every 10 minutes,
lets see how far this can go just for fun :-)
Been looking into some existant sshd implementations in go. Most of the
projects on github seem to use the standard x/crypto/ssh lib.
During testing, i just wanted to see which banner these kind of ssh servers
provide, using the simple command:
Besides several bugfixes, the latest version now supports using higher
compression levels and logging to syslog facility. I also finished packaging
and official packages are now available,
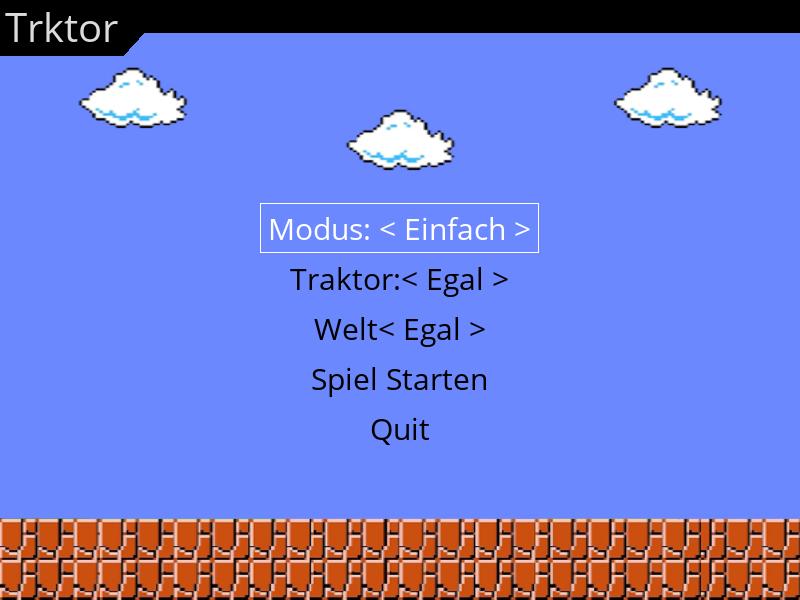
Next year my son will turn 4. I have quit playing computer games for a pretty
long time now, but recently i questioned myself: what will be the first
computer game hes going to play? Why not create a simple game by myself?
Living on the landside, his attention has been drawn to farming machines
for quite some time now and that topic never grows old for him, which
makes for a perfect game setting.
The game logic should be pretty simple: A tiling 2d jump game where you have to
make an tractor jump over appearing objects. Different vehicles and backgrounds
to choose and a set of lives with randomly generated coins which you have
to catch to undo happened failures.
Never having done anything related to pygame the learning curve has been quite
good so far :-)
The part i spent most time with was searching for free assets and pixel art
which im able to use. Gimp also made me lose quite some hair while failing to
canvas/crop images to the right size so the placements within the different
maps matched..
I used pyinstaller to make it somewhat portable (needs to run on windows too)
and building the artifacts using github actions was quite a nice experience..
Lets see where this goes next, lots of ideas come to my mind :)
https://github.com/abbbi/trktor
Had some time to add more features to my libvirt backup utility, now it
supports:
backing up virtual domains UEFI bios, initrd and kernel images if
defined.
virtnbdmap now uses the nbdkit COW plugin to map the backups as regular
NBD device. This allows users to replay complete backup chains
(full+inc/diff) to recover single files. Also makes the mapped device
writable, as such one can directly boot the virtual machine from the backup
images.
Check out my last article on that
topic or watch it in action.
As a side note: still there s an RFP open,
if one is interested in maintaining, as i find myself not having a valid
key in the keyring.. laziness.
Had some time to add more features to my libvirt backup utility, now it
supports:
Added backup mode differencial.
Save virtual domains UEFI bios, initrd and kernel images if defined.
virtnbdmap now uses the nbdkit COW plugin to map the backups as regular
NBD device. This allows users to replay complete backup chains
(full+inc/diff) to recover single files. As the resulting device is
writable, one can directly boot the virtual machine from the backup
images.
Check out my last article on that
topic or watch it in action.
Also, the dirty bitmap (incremental backup) feature now seems to be enabled by
default as of newer qemu and libvirt (8.2.x) versions.
As a side note: still there s an RFP open,
if one is interested in maintaining, as i find myself not having a valid
key in the keyring.. laziness.
Everyone knows that an application exit code should change based on
the success, error or maybe warnings that happened during execution.
Lately i came along some python code that was structured the following way:
#!/usr/bin/python3
importsysimportloggingdefwarnme():# something bad happens
logging.warning("warning")sys.exit(2)defevil():# something evil happens
logging.error("error")sys.exit(1)defmain():logging.basicConfig(level=logging.DEBUG,)[..]
the situation was a little bit more complicated, some functions in other
modules also exited the application, so sys.exit() calls were distributed
in lots of modules an files.
Exiting the application in some random function of another module is
something i dont consider nice coding style, because it makes it hard
to track down errors.
I expect:
exit code 0 on success
exit code 1 on errors
exit code 2 on warnings
warnings or errors shall be logged in the function where they actually
happen: the logging module will show the function name with a better
format option: nice for debugging.
one function that exits accordingly, preferrably main()
How to do better?
As the application is using the logging module, we have a single point to
collect warnings and errors that might happen accross all modules. This works
by passing a custom handler to the logging module which tracks emitted
messages.
Heres an small example:
#!/usr/bin/python3
importsysimportloggingclasslogCount(logging.Handler):classLogType:def__init__(self):self.warnings=0self.errors=0def__init__(self):super().__init__()self.count=self.LogType()defemit(self,record):ifrecord.levelname=="WARNING":self.count.warnings+=1ifrecord.levelname=="ERROR":self.count.errors+=1definfome():logging.info("hello world")defwarnme():logging.warning("help, an warning")defevil():logging.error("yikes")defmain():EXIT_WARNING=2EXIT_ERROR=1counter=logCount()logging.basicConfig(level=logging.DEBUG,handlers=[counter,logging.StreamHandler(sys.stderr)],)infome()warnme()evil()ifcounter.count.errors!=0:raiseSystemExit(EXIT_ERROR)ifcounter.count.warnings!=0:raiseSystemExit(EXIT_WARNING)if__name__=="__main__":main()
python3 count.py ;echo$?
INFO:root:hello world
WARNING:root:help, an warning
ERROR:root:yikes
1
This also makes easy to define something like:
hey, got 2 warnings, change exit code to error?
got 3 warnings, but no strict passed, ingore those, exit with success!
fs.com s5850 and s8050 series type switches have a secret mode which
lets you enter a regular shell from the switch cli, like so:
hostname# start shell
Password:
The command and password are not documented by the manufacturer,
i wondered wether if its possible to extract that password from
the firmware. After all: its my device, and i want to have access
to all the features!
Download the latest firmware image for those switch types and let binwalk do
its magic:
In my last article i showed how to use the
new features included in Debian Bullseye to easily create backups of your
libvirt managed domains.
A few years ago as this topic came to my interest, i also implemented a rather
small utility (POC) to create full and incremental backups from standalone qemu
processes: qmpbackup
The workflow for this is a little bit different from the approach i have taken
with virtnbdbackup.
While with libvirt managed virtual machines, the libvirt API provides all
necessary API calls to create backups, a running qemu process only provides the
QMP protocol socket to get things going.
Using the QMP protocol its possible to create bitmaps for the attached disks
and make Qemu push the contents of the bitmaps to a specified target directory.
As the bitmaps keep track of the changes on the attached block devices, you can
create incremental backups too.
The nice thing here is that the Qemu process actually does this all by itself
and you dont have to care about which blocks are dirty, like you would have
to do with the Pull based approach.
So how does it work?
The utility requires to start your qemu process with an active QMP socket
attached, like so:
Now you can easily make qemu push the latest data for a created bitmap
to a given target directory:
# qmpbackup --socket /tmp/socket backup --level full --target /tmp/backup/[2022-01-27 19:41:33,819] INFO Version: 0.10
[2022-01-27 19:41:33,819] INFO Qemu version: [5.0.2] [Debian 1:5.2+dfsg-11+deb11u1]
[2022-01-27 19:41:33,825] INFO Guest Agent socket connected
[2022-01-27 19:41:33,825] INFO Trying to ping guest agent
[2022-01-27 19:41:38,827] WARNING Unable to reach Guest Agent: cant freeze file systems.
[2022-01-27 19:41:38,828] INFO Backup target directory: /tmp/backup/
[2022-01-27 19:41:38,828] INFO FULL Backup operation: "/tmp/backup//ide0-hd0/FULL-1643308898"[2022-01-27 19:41:38,836] INFO Wrote Offset: 0% (0 of 2147483648)[2022-01-27 19:41:39,838] INFO Wrote Offset: 25% (541065216 of 2147483648)[2022-01-27 19:41:40,840] INFO Wrote Offset: 33% (701890560 of 2147483648)[2022-01-27 19:41:41,841] INFO Wrote Offset: 40% (867041280 of 2147483648)[2022-01-27 19:41:42,844] INFO Wrote Offset: 50% (1073741824 of 2147483648)[2022-01-27 19:41:43,846] INFO Wrote Offset: 59% (1269760000 of 2147483648)[2022-01-27 19:41:44,847] INFO Wrote Offset: 75% (1610612736 of 2147483648)[2022-01-27 19:41:45,848] INFO Saved disk: [ide0-hd0]
The resulting directory now contains a full backup image of the disk attached.
From this point on, its possible to create further incremental backups:
# qmpbackup --socket /tmp/socket backup --level inc --target /tmp/backup/[2022-01-27 19:42:03,930] INFO Version: 0.10
[2022-01-27 19:42:03,931] INFO Qemu version: [5.0.2] [Debian 1:5.2+dfsg-11+deb11u1]
[2022-01-27 19:42:03,933] INFO Guest Agent socket connected
[2022-01-27 19:42:03,933] INFO Trying to ping guest agent
[2022-01-27 19:42:08,938] WARNING Unable to reach Guest Agent: cant freeze file systems.
[2022-01-27 19:42:08,939] INFO Backup target directory: /tmp/backup/
[2022-01-27 19:42:08,939] INFO INC Backup operation: "/tmp/backup//ide0-hd0/INC-1643308928"[2022-01-27 19:42:08,953] INFO Wrote Offset: 0% (0 of 1835008)[2022-01-27 19:42:09,957] INFO Saved disk: [ide0-hd0]
The target directory will now have multiple data backups:
Restoring the image
Using the qmprebase utility you can now rebase the images to the latest
state. The --dry-run option gives an good impression which command sequences
are required, if one wants only rebase to a specific incremental backup, thats
possible using the --until option.
# qmprebase rebase --dir /tmp/backup/ide0-hd0/ --dry-run[2022-01-27 17:18:08,790] INFO Version: 0.10
[2022-01-27 17:18:08,790] INFO Dry run activated, not applying any changes
[2022-01-27 17:18:08,790] INFO qemu-img check /tmp/backup/ide0-hd0/INC-1643308928
[2022-01-27 17:18:08,791] INFO qemu-img rebase -b"/tmp/backup/ide0-hd0/FULL-1643308898""/tmp/backup/ide0-hd0/INC-1643308928"-u[2022-01-27 17:18:08,791] INFO qemu-img commit "/tmp/backup/ide0-hd0/INC-1643308928"[2022-01-27 17:18:08,791] INFO Rollback of latest [FULL]<-[INC] chain complete, ignoring older chains
[2022-01-27 17:18:08,791] INFO Image files rollback successful.
Filesystem consistency
The backup utility also supports to freeze and thaw the virtual machines file
system in case qemu is started with a guest agent socket and the guest agent is
reachable during backup operation.
Check out the README for the full
feature set.
The libvirt and qemu versions in Debian Bullseye support a new feature that
allows for easier backup and recovery of virtual machines. Instead of using
snapshots for backup operation, its now possible to enable dirty
bitmaps. Other
hypervisors tend to call this changed block tracking .
Using the new backup
begin approach, its not
only possible to create live full backups (without having to create an
snapshot) but also track the changes between so called checkpoints,
which is very useful for incremental backups.
Over the course of the last few months, i have been working on a
simple backup and recovery utility called virtnbdbackup
It uses the pull based approach in the libvirt api set and currently
supports:
Thin provisioned full and incremental backups.
Compression (lz4).
Freezing the virtual machine guest fs via qemu-agent (if installed)
Multithreaded backup, if multiple disks are attached.
Point in time recovery to a given incremental backup.
Includes nbdkit plugin and utility that allows to map the thin provisioned
backup images to a block device, for single file or instant recovery (boot
the virtual machine directly from the backup image)
Preparing the virtual machines
The dirty bitmap feature is not enabled by default, users can enable
it by adding a new capability to a virtual machine configuration:
To finally enable the feature, power cycle virtual machine once.
Creating backups
By default, virtnbdbackup saves the virtual machine config, disks and
its logfiles to a given target directory. Its also possible to stream
the output into a uncompressed zip archive
Taking a backup is as simple as:
# virtnbdbackup -d vm2 -l full -o /tmp/WEEKLY_BACKUP/[..]
[2021-11-08 15:43:46] INFO virtnbdbackup - main [MainThread]: Backup jobs finished, stopping backup task.
[2021-11-08 15:43:46] INFO virtnbdbackup - main [MainThread]: Finished
# tree /tmp/WEEKLY_BACKUP/
/tmp/WEEKLY_BACKUP/
backup.full.11082021154343.log
checkpoints
virtnbdbackup.0.xml
sda.full.data
vm2.cpt
vmconfig.virtnbdbackup.0.xml
From that point on, its now possible to create incremental backups:
Restoring backups
The virtnbdrestore utility can be used to reconstruct the backup sets
into usable qcow images, like so:
# virtnbdrestore -a restore -i /tmp/WEEKLY_BACKUP/ -o /tmp/VM_RESTORE
Using the --until option its also possible to only reconstruct the
images to a certain checkpoint, allowing for point in time recovery.
Restoring single files
Via virtnbdmap you can map full backups back into an usable block device,
without having to reconstruct the complete backup image:
# virtnbdmap -f /tmp/WEEKLY_BACKUP/sda.full.data[..] INFO virtnbdmap - <module> [MainThread]: Done mapping backup image to [/dev/nbd0]
[..] INFO virtnbdmap - <module> [MainThread]: Press CTRL+C to disconnect
# fdisk -l /dev/nbd0
Disk /dev/nbd0: 2 GiB, 2147483648 bytes, 4194304 sectors
From here, you can either mount the disc and recover single files, or boot
from it via:
Welcome to this 5th issue of the DeFuBu contest, the monthly championship of the funniest bug reported to the Debian BTS.
The challengers
Pierre Habouzit with #395522(whitelister terminates immediately)
Josselin Mouette with #396247(sound-juicer: weird playback if disk is ejected)
Christian Perrier with #396223(gnome-applets-data: Colorado Springs listed as "Colourado Springs" in British English)
Joey Hess with #393846(wave at a webcam to overwrite file)
Michael Ablassmeier with #397646(exim4-config: reportbug mail issue)
How the vote has been done
Four Debian related people voted for these bugs, Philipp Kern, Julien Louis, Cyril Brulebois and David Pashley.
Full ranking
Bugs
#393846(wave at a webcam to overwrite file) (with 12 points)
#396223(gnome-applets-data: Colorado Springs listed as "Colourado Springs" in British English) (with 10 points)
#396247(sound-juicer: weird playback if disk is ejected) (with 9 points)
#397646(exim4-config: reportbug mail issue) (with 9 points)
I'd love to hear the reason.
Update: Michael Ablassmeier pointed me to a pretty good analysis.
Update 2: The title is actually courtesy of Ari. My bad.
Debian again hat a booth at the "Systems" fair in Munich. This is mostly a
B2B fair, and the focus is on "ready to use" products. So there are few new
product announcements happening here, and not this big audience as of IFA
or CeBIT. Still it is an important fair for the medium and small sized
businesses. Noone expects a PSP to be introduced there...
I staffed the booth on tuesday morning, and I intended to staff it on Friday
morning, too (but was unable to do so). We were rather few people this year;
also the organizational contribution of Jens (who died this summer) was missed
a lot. Thanks to Michael Banck for organizing most things, and to all the other
contributors such as Michael Ablassmeier and Simon Richter. See
Michael
Bancks blog posting for a complete list. Thanks also to e.g. the wikipedia
staff, who managed to staff our booth for a few minutes while I went to the
entrance to give Simon a free pass.
Tuesday morning was rather quiet, few people coming by, most of which are
either already happy Debian users or at least know of it. Few donations,
albeit the few LinuxTag DVDs left were gone (for a donation of at least 2 Euro)
by noon. While I remember people asking all the time about the pretty posters
with Ayo's artwork last year, and we had
a bigger stock of them this time, noone asked while I was there.
So on overall, I don't think it paid off for the project. :-(
A couple of people had technical questions which I was usually able to give
the relevant pointers for solving them. The recurring question "when is sarge
going to be released" was obviously not an issue any more; one guy asked when
etch was going to be released and I was able to quickly pull out the
announcement by the release team with the end-of-2006 schedule.
I was rather disappointed with the few people coming by, but probably tuesday
morning was a rather unrepresentative time. The only two "important"
conversations I had there was with someone from a PHP magazine who are
interested in including a Sarge+PHP5+MySQL5 CD with an upcoming issue (I can't
do that, I hope they'll find someone else to prepare the CD for them!) and
with the people from LiMux (the upcoming linux switch of the city of munich)
which sounded (to me) much like the current delay of the project is mostly due
to management issues than due to Debian/GNU/Linux lacking some features. They
couldn't really tell me what the Debian project could do to support LiMux.
Debian being used for LiMux is something I'm really looking forward to, and
I would have loved to see a demo of it at the Systems, but apparently the
project isn't that far yet. :-(
I didn't see much of the Systems otherwise - I had to hurry back to the
university when I left the booth, so I didn't visit any other booth. The
last few times it wasn't too interesting for me anyway, since none of the
products (except the OSS projects) is targeted at my audience obviously. And
I'm not the type to walk around to collect as many free CDs and ball pens as
possible. I remember that last year you could have your face "imprinted" in a
block of transparent resin with small bubbles or so; no idea if that was free
or at a low charge, though. You used to get popcorn and such stuff at a couple
of booths etc. - and a lot more of such stuff back in DotCom times - but it
never interested me too much. And last year I think a conference hotel had
the booth opposite of us and gave away free beer... anyway, I didn't even
check if the LiMux booth maybe had one of these nice munich-penguin pins...
I had considered to walk around and ask for sponsorship at a coupld of places
for some projects I'm invovled in, but I don't think I'm good at that anyway...
So my feelings are rather mixed. I really hope we'll have more people for the
booth next year, because I'll not be available then: I'll hopefully be in
finishing my diploma thesis by then.
 Now copy the ISO image to the newly created instance and extract
its data:
Now copy the ISO image to the newly created instance and extract
its data:
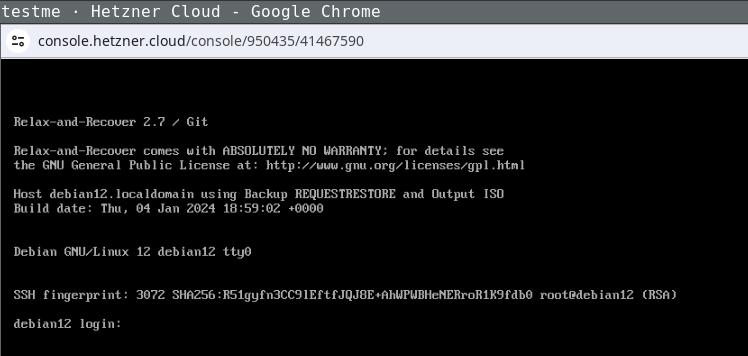 Login the recovery console (root without password) and fix its default route to
make it reachable:
Login the recovery console (root without password) and fix its default route to
make it reachable:
 Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
 After performing the required tests within the virtual machine we can simply
kill the active NBD backup job :
After performing the required tests within the virtual machine we can simply
kill the active NBD backup job :








 https://github.com/abbbi/trktor
https://github.com/abbbi/trktor
 Welcome to this 5th issue of the DeFuBu contest, the monthly championship of the funniest bug reported to the
Welcome to this 5th issue of the DeFuBu contest, the monthly championship of the funniest bug reported to the