
A good amount of the Debian
reproducible
builds team had the chance to
enjoy face-to-face interactions during
DebConf15.
Names in red and blue were all present at DebConf15 |
Hugging people with whom one has been working tirelessly for months gives a lot of warm-fuzzy feelings. Several recorded and hallway discussions paved the way to solve the remaining issues to get reproducible builds part of Debian proper. Both talks from the
Debian Project Leader and the
release team mentioned the effort as important for the future of Debian.
A
forty-five minutes talk presented the state of the reproducible builds effort. It was then followed by an
hour long roundtable to discuss current blockers regarding
dpkg,
.buildinfo and their integration in the archive.

Toolchain fixes
- Kenneth J. Pronovici uploaded epydoc/3.0.1+dfsg-12 which makes class and modules ordering predictable (#795835) and fixes
__repr__ so memory addresses don't appear in docs (#795826). Patches by Val Lorentz.
- Sergei Golovan uploaded erlang/1:18.0-dfsg-2 which adds support for SOURCE_DATE_EPOCH to
erlc. Patch by Chris West (Faux) and Chris Lamb.
- Dmitry Shachnev uploaded sphinx/1.3.1-5 which make grammar, inventory, and JavaScript locales generation deterministic. Original patch by Val Lorentz.
- St phane Glondu uploaded ocaml/4.02.3-2 to experimental, making startup files and native packed libraries deterministic. The patch adds deterministic
.file to the assembler output.
- Enrico Tassi uploaded lua-ldoc/1.4.3-3 which now pass the
-d option to txt2man and add the --date option to override the current date.
Reiner Herrmann
submitted a patch to make
rdfind sort the processed files before doing any operation. Chris Lamb proposed a
new patch for
wheel implementing support for
SOURCE_DATE_EPOCH instead of the custom
WHEEL_FORCE_TIMESTAMP. akira
sent one making
man2html SOURCE_DATE_EPOCH aware.
St phane Glondu reported that
dpkg-source would not respect tarball permissions when unpacking under a umask of 002.
After hours of iterative testing during the DebConf workshop, Sandro Knau
created a test case showing how
pdflatex output can be non-deterministic with some PNG files.
Packages fixed
The following 65 packages became reproducible due to changes in their
build dependencies:
alacarte,
arbtt,
bullet,
ccfits,
commons-daemon,
crack-attack,
d-conf,
ejabberd-contrib,
erlang-bear,
erlang-cherly,
erlang-cowlib,
erlang-folsom,
erlang-goldrush,
erlang-ibrowse,
erlang-jiffy,
erlang-lager,
erlang-lhttpc,
erlang-meck,
erlang-p1-cache-tab,
erlang-p1-iconv,
erlang-p1-logger,
erlang-p1-mysql,
erlang-p1-pam,
erlang-p1-pgsql,
erlang-p1-sip,
erlang-p1-stringprep,
erlang-p1-stun,
erlang-p1-tls,
erlang-p1-utils,
erlang-p1-xml,
erlang-p1-yaml,
erlang-p1-zlib,
erlang-ranch,
erlang-redis-client,
erlang-uuid,
freecontact,
givaro,
glade,
gnome-shell,
gupnp,
gvfs,
htseq,
jags,
jana,
knot,
libconfig,
libkolab,
libmatio,
libvsqlitepp,
mpmath,
octave-zenity,
openigtlink,
paman,
pisa,
pynifti,
qof,
ruby-blankslate,
ruby-xml-simple,
timingframework,
trace-cmd,
tsung,
wings3d,
xdg-user-dirs,
xz-utils,
zpspell.
The following packages became reproducible after getting fixed:
- apr/1.5.2-3 by Stefan Fritsch.
- aprx/2.08.svn593+dfsg-2 uploaded by Colin Tuckley, original patch by Chris Lamb.
- blkreplay/1.0-3 uploaded by Andrew Shadura, patch by Dhole.
- cal3d/0.11.0-6 uploaded by Manuel A. Fernandez Montecelo, patch by akira.
- cgsi-gsoap/1.3.8-1 by Mattias Ellert.
- eyefiserver/2.4+dfsg-1 by Jean-Michel Vourg re.
- gnujump/1.0.8-3 uploaded by Evgeni Golov, original patch by Chris Lamb.
- hkgerman/1:2-29 by Roland Rosenfeld.
- jove/4.16.0.73-4 by Cord Beermann.
- libevhtp/1.2.10-3 by Vincent Bernat.
- libmkdoc-xml-perl/0.75-4 uploaded by gregor herrmann, original patch by Niko Tyni.
- libparse-debianchangelog-perl/1.2.0-6 by Niko Tyni.
- librostlab-blast/1.0.1-5 uploaded by Andreas Tille, original patch by Chris Lamb.
- libxray-absorption-perl/3.0.1-3 uploaded by gregor herrmann, original patch by Niko Tyni.
- lua-penlight/1.3.2-2 by Enrico Tassi.
- mosquitto/1.4.3-1 by Roger A. Light.
- nagios-plugins-contrib/15.20150818 by Jan Wagner and Bernd Zeimetz.
- nn/6.7.3-10 uploaded by Cord Beermann, original patch by Chris Lamb.
- pybik/2.1-1 by B. Clausius.
- pyepr/0.9.3-1 uploaded by Antonio Valentino, original patch by Juan Picca.
- python-xlrd/0.9.4-1 by Vincent Bernat.
- transmissionrpc/0.11-2 uploaded by Vincent Bernat, original patch by Juan Picca.
- unoconv/0.7-1.1 sponsored by Vincent Bernat, fix by Dhole.
- vim-latexsuite/20141116.812-1 uploaded by Johann Felix Soden, original patch by Chris Lamb.
- volk/1.0.2-2 by A. Maitland Bottoms.
- xbmc/2:13.2+dfsg1-5 by Balint Reczey.
- xdotool/1:3.20150503.1-2 uploaded by Daniel Kahn Gillmor, initial patch by Chris Lamb.
- xfig/1:3.2.5.c-5 by Roland Rosenfeld.
- xfireworks/1.3-10 uploaded by Yukiharu YABUKI, original patch by Chris Lamb.
- xul-ext-monkeysphere/0.8-2 uploaded by Daniel Kahn Gillmor, original patch by Dhole.
Uploads that might have fixed reproducibility issues:
Some uploads fixed some reproducibility issues but not all of them:
Patches submitted which have not made their way to the archive yet:
- #795861 on fakeroot by Val Lorentz: set the mtime of all files to the time of the last
debian/changelog entry.
- #795870 on fatresize by Chris Lamb: set build date to the time of the latest
debian/changelog entry.
- #795945 on projectl by Reiner Herrmann: sort with
LC_ALL set to C.
- #795977 on dahdi-tools by Dhole: set the timezone to UTC before calling asciidoc.
- #795981 on x11proto-input by Dhole: set the timezone to UTC before calling asciidoc.
- #795983 on dbusada by Dhole: set the timezone to UTC before calling asciidoc.
- #795984 on postgresql-plproxy by Dhole: set the timezone to UTC before calling asciidoc.
- #795985 on xorg by Dhole: set the timezone to UTC before calling asciidoc.
- #795987 on pngcheck by Dhole: set the date in the man pages to the latest
debian/changelog entry.
- #795997 on python-babel by Val Lorentz: make build timestamp independent from the timezone and remove the name of the build system locale from the documentation.
- #796092 on a7xpg by Reiner Herrmann: sort with
LC_ALL set to C.
- #796212 on bittornado by Chris Lamb: remove umask-varying permissions.
- #796251 on liblucy-perl by Niko Tyni: generate
lib/Lucy.xs in a deterministic order.
- #796271 on tcsh by Reiner Herrmann: sort with
LC_ALL set to C.
- #796275 on hspell by Reiner Herrmann: remove timestamp from
aff files generated by mk_he_affix.
- #796324 on fftw3 by Reiner Herrmann: remove date from documentation files.
- #796335 on nasm by Val Lorentz: remove extra timestamps from the build system.
- #796360 on libical by Chris Lamb: removes randomess caused Perl in generated
icalderivedvalue.c.
- #796375 on wcd by Dhole: set the date in the man pages to the latest
debian/changelog entry.
- #796376 on mapivi by Dhole: set the date in the man pages to the latest
debian/changelog entry.
- #796527 on vserver-debiantools by Dhole: set the date in the man pages to the latest
debian/changelog entry.
St phane Glondu reported two issues regarding embedded build date in
omake and
cduce.
Aur lien Jarno
submitted a fix for the breakage of
make-dfsg test suite. As
binutils now creates deterministic libraries by default, Aur lien's patch makes use of a wrapper to give the
U flag to
ar.
Reiner Herrmann reported
an issue with
pound which embeds random
dhparams in its code during the build. Better solutions are yet to be found.
reproducible.debian.net
Package pages on
reproducible.debian.net now have a new layout improving readability designed by Mattia Rizzolo, h01ger, and Ulrike. The navigation is now on the left as vertical space is more valuable nowadays.
armhf is now enabled on all pages except the dashboard. Actual tests on
armhf are expected to start shortly. (Mattia Rizzolo, h01ger)
The limit on how many packages people can schedule using the
reschedule script on Alioth has been bumped to 200. (h01ger)
mod_rewrite is now used instead of JavaScript for the form in the dashboard. (h01ger)
Following the rename of the software, debbindiff has mostly been replaced by either diffoscope or differences in generated HTML and IRC notification output.
Connections to
UDD have been made more robust. (Mattia Rizzolo)
diffoscope development
diffoscope version 31 was released on August 21
st. This version improves fuzzy-matching by using the
tlsh algorithm instead of
ssdeep.
New command line options are available:
--max-diff-input-lines and
--max-diff-block-lines to override limits on
diff input and output (Reiner Herrmann),
--debugger to dump the user into pdb in case of crashes (Mattia Rizzolo).
jar archives should now be detected properly (Reiner Herrman). Several general code cleanups were also done by Chris Lamb.
strip-nondeterminism development
Andrew Ayer released
strip-nondeterminism version 0.010-1. Java properties file in jar should now be detected more accurately. A missing dependency spotted by St phane Glondu has been added.
Testing directory ordering issues: disorderfs
During the reproducible builds workshop at DebConf, participants identified that we were still short of a good way to test variations on filesystem behaviors (e.g. file ordering or disk usage). Andrew Ayer took a couple of hours to create
disorderfs. Based on
FUSE,
disorderfs in an overlay filesystem that will mount the content of a directory at another location. For this first version, it will make the order in which files appear in a directory random.
Documentation update
Dhole
documented how to implement support for
SOURCE_DATE_EPOCH in Python, bash,
Makefiles, CMake, and C.
Chris Lamb started to convert the wiki page describing
SOURCE_DATE_EPOCH into a Freedesktop-like specification in the hope that it will convince more upstream to adopt it.
Package reviews
44
reviews have
been removed, 192 added and 77 updated this week.
New issues identified this week:
locale_dependent_order_in_devlibs_depends,
randomness_in_ocaml_startup_files,
randomness_in_ocaml_packed_libraries,
randomness_in_ocaml_custom_executables,
undeterministic_symlinking_by_rdfind,
random_build_path_by_golang_compiler, and
images_in_pdf_generated_by_latex.
117 new FTBFS bugs have been reported by Chris Lamb, Chris West (Faux), and Niko Tyni.
Misc.
Some reproducibility issues might face us very late. Chris Lamb noticed that the test suite for
python-pykmip was now
failing because its test certificates have expired. Let's hope no packages are hiding a certificate valid for 10 years somewhere in their source!
Pictures courtesy and copyright of Debian's own paparazzi: Aigars Mahinovs.
 Sometimes you need to do things you don't like and you don't know where you will end up.
Sometimes you need to do things you don't like and you don't know where you will end up. Since some time everybody (read developer) want to run his new
Since some time everybody (read developer) want to run his new 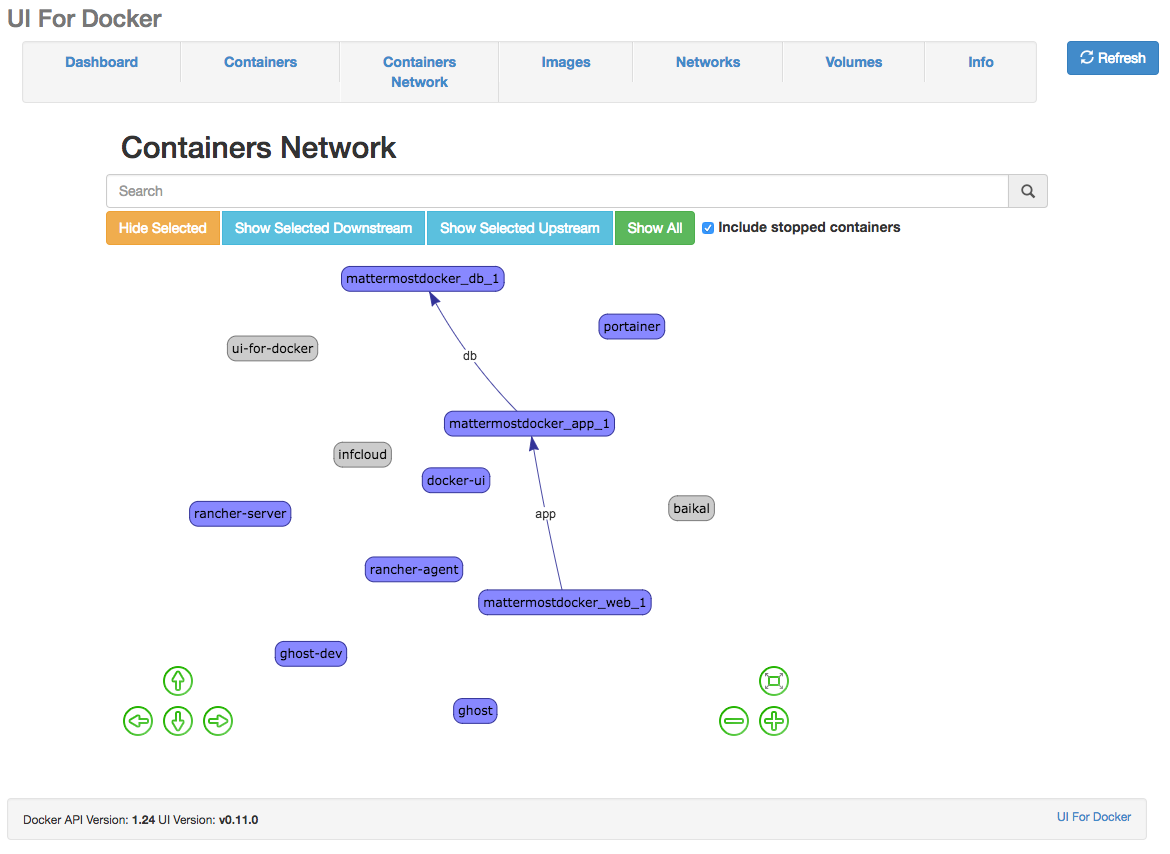
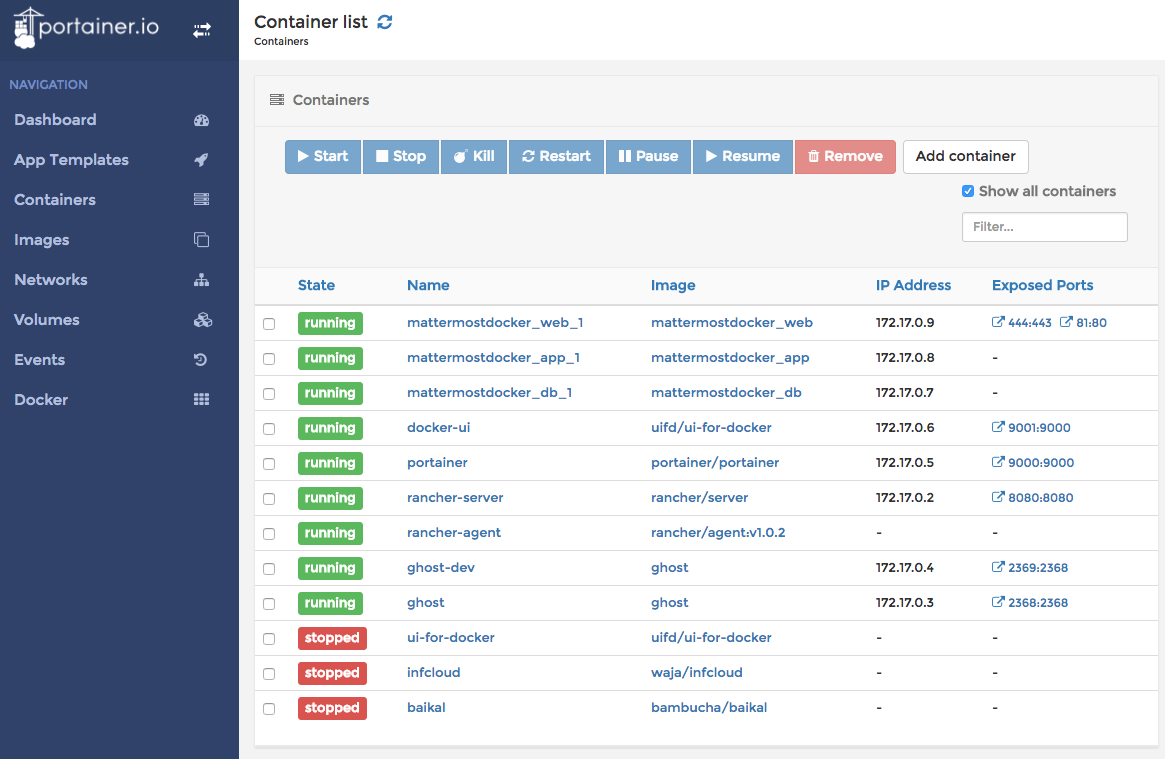
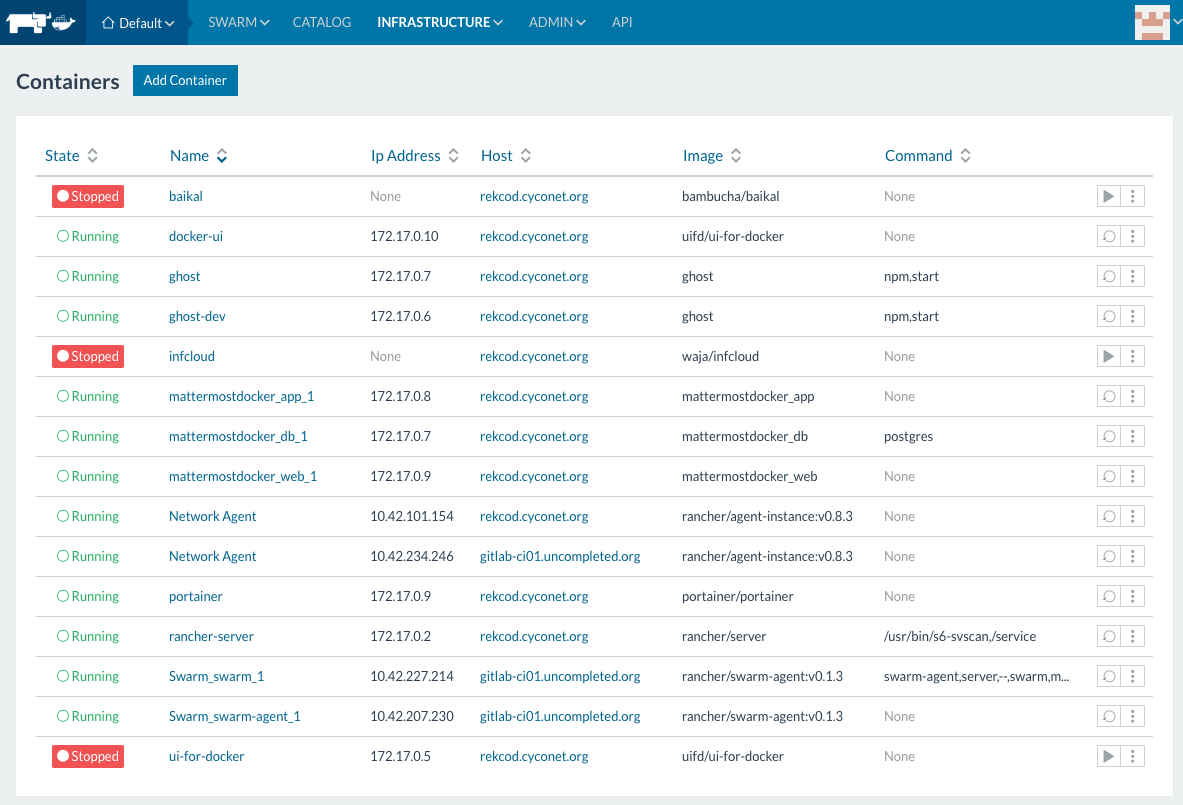 For the use cases, we are facing,
For the use cases, we are facing, 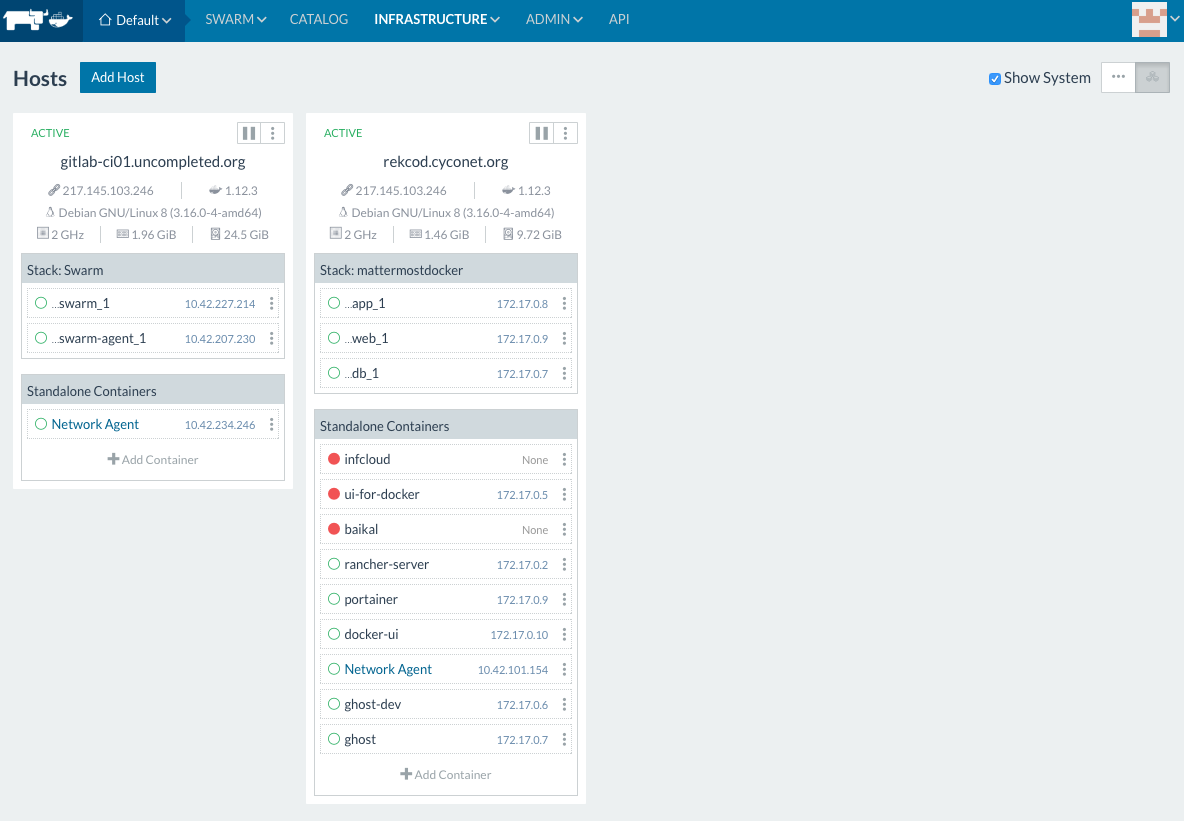
 When looking around to implement a nginx in front of a Docker web application, in most cases nginx itself is also a Docker container.
When looking around to implement a nginx in front of a Docker web application, in most cases nginx itself is also a Docker container. 

 Looking into this with
Looking into this with 



 In case you have spare time at the weekend ahead, it may be worth to spend it with great
In case you have spare time at the weekend ahead, it may be worth to spend it with great