Ian Jackson: Why we ve voted No to CfD for Derril Water solar farm
- Green electricity from your mainstream supplier is a lie
- Ripple
- Contracts for Difference
- Ripple and CfD
- Voting No
 Dear Debianites
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on debian-vote, it takes quite a bit of restraint to not
answer all of them myself, I think I can see how that aspect contributed
to me being reeled in to running for DPL! In total I've done so 5 times
(the first time I ran, Sam was elected!).
Good luck to both Andreas and Sruthi, our current
DPL candidates! I've already started working on preparing handover, and
there's multiple request from teams that have came in recently that will
have to wait for the new term, so I hope they're both ready to hit the
ground running!
Things that I wish could have gone better
Communication
Recently, I saw a t-shirt that read:
Dear Debianites
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on debian-vote, it takes quite a bit of restraint to not
answer all of them myself, I think I can see how that aspect contributed
to me being reeled in to running for DPL! In total I've done so 5 times
(the first time I ran, Sam was elected!).
Good luck to both Andreas and Sruthi, our current
DPL candidates! I've already started working on preparing handover, and
there's multiple request from teams that have came in recently that will
have to wait for the new term, so I hope they're both ready to hit the
ground running!
Things that I wish could have gone better
Communication
Recently, I saw a t-shirt that read:
Adulthood is saying, 'But after this week things will slow down a bit' over and over until you die.I can relate! With every task, crisis or deadline that appears, I think that once this is over, I'll have some more breathing space to get back to non-urgent, but important tasks. "Bits from the DPL" was something I really wanted to get right this last term, and clearly failed spectacularly. I have two long Bits from the DPL drafts that I never finished, I tend to have prioritised problems of the day over communication. With all the hindsight I have, I'm not sure which is better to prioritise, I do rate communication and transparency very highly and this is really the top thing that I wish I could've done better over the last four years. On that note, thanks to people who provided me with some kind words when I've mentioned this to them before. They pointed out that there are many other ways to communicate and be in touch with the community, and they mentioned that they thought that I did a good job with that. Since I'm still on communication, I think we can all learn to be more effective at it, since it's really so important for the project. Every time I publicly spoke about us spending more money, we got more donations. People out there really like to see how we invest funds in to Debian, instead of just making it heap up. DSA just spent a nice chunk on money on hardware, but we don't have very good visibility on it. It's one thing having it on a public line item in SPI's reporting, but it would be much more exciting if DSA could provide a write-up on all the cool hardware they're buying and what impact it would have on developers, and post it somewhere prominent like debian-devel-announce, Planet Debian or Bits from Debian (from the publicity team). I don't want to single out DSA there, it's difficult and affects many other teams. The Salsa CI team also spent a lot of resources (time and money wise) to extend testing on AMD GPUs and other AMD hardware. It's fantastic and interesting work, and really more people within the project and in the outside world should know about it! I'm not going to push my agendas to the next DPL, but I hope that they continue to encourage people to write about their work, and hopefully at some point we'll build enough excitement in doing so that it becomes a more normal part of our daily work. Founding Debian as a standalone entity This was my number one goal for the project this last term, which was a carried over item from my previous terms. I'm tempted to write everything out here, including the problem statement and our current predicaments, what kind of ground work needs to happen, likely constitutional changes that need to happen, and the nature of the GR that would be needed to make such a thing happen, but if I start with that, I might not finish this mail. In short, I 100% believe that this is still a very high ranking issue for Debian, and perhaps after my term I'd be in a better position to spend more time on this (hmm, is this an instance of "The grass is always better on the other side", or "Next week will go better until I die?"). Anyway, I'm willing to work with any future DPL on this, and perhaps it can in itself be a delegation tasked to properly explore all the options, and write up a report for the project that can lead to a GR. Overall, I'd rather have us take another few years and do this properly, rather than rush into something that is again difficult to change afterwards. So while I very much wish this could've been achieved in the last term, I can't say that I have any regrets here either. My terms in a nutshell COVID-19 and Debian 11 era My first term in 2020 started just as the COVID-19 pandemic became known to spread globally. It was a tough year for everyone, and Debian wasn't immune against its effects either. Many of our contributors got sick, some have lost loved ones (my father passed away in March 2020 just after I became DPL), some have lost their jobs (or other earners in their household have) and the effects of social distancing took a mental and even physical health toll on many. In Debian, we tend to do really well when we get together in person to solve problems, and when DebConf20 got cancelled in person, we understood that that was necessary, but it was still more bad news in a year we had too much of it already. I can't remember if there was ever any kind of formal choice or discussion about this at any time, but the DebConf video team just kind of organically and spontaneously became the orga team for an online DebConf, and that lead to our first ever completely online DebConf. This was great on so many levels. We got to see each other's faces again, even though it was on screen. We had some teams talk to each other face to face for the first time in years, even though it was just on a Jitsi call. It had a lasting cultural change in Debian, some teams still have video meetings now, where they didn't do that before, and I think it's a good supplement to our other methods of communication. We also had a few online Mini-DebConfs that was fun, but DebConf21 was also online, and by then we all developed an online conference fatigue, and while it was another good online event overall, it did start to feel a bit like a zombieconf and after that, we had some really nice events from the Brazillians, but no big global online community events again. In my opinion online MiniDebConfs can be a great way to develop our community and we should spend some further energy into this, but hey! This isn't a platform so let me back out of talking about the future as I see it... Despite all the adversity that we faced together, the Debian 11 release ended up being quite good. It happened about a month or so later than what we ideally would've liked, but it was a solid release nonetheless. It turns out that for quite a few people, staying inside for a few months to focus on Debian bugs was quite productive, and Debian 11 ended up being a very polished release. During this time period we also had to deal with a previous Debian Developer that was expelled for his poor behaviour in Debian, who continued to harass members of the Debian project and in other free software communities after his expulsion. This ended up being quite a lot of work since we had to take legal action to protect our community, and eventually also get the police involved. I'm not going to give him the satisfaction by spending too much time talking about him, but you can read our official statement regarding Daniel Pocock here: https://www.debian.org/News/2021/20211117 In late 2021 and early 2022 we also discussed our general resolution process, and had two consequent votes to address some issues that have affected past votes: In my first term I addressed our delegations that were a bit behind, by the end of my last term all delegation requests are up to date. There's still some work to do, but I'm feeling good that I get to hand this over to the next DPL in a very decent state. Delegation updates can be very deceiving, sometimes a delegation is completely re-written and it was just 1 or 2 hours of work. Other times, a delegation updated can contain one line that has changed or a change in one team member that was the result of days worth of discussion and hashing out differences. I also received quite a few requests either to host a service, or to pay a third-party directly for hosting. This was quite an admin nightmare, it either meant we had to manually do monthly reimbursements to someone, or have our TOs create accounts/agreements at the multiple providers that people use. So, after talking to a few people about this, we founded the DebianNet team (we could've admittedly chosen a better name, but that can happen later on) for providing hosting at two different hosting providers that we have agreement with so that people who host things under debian.net have an easy way to host it, and then at the same time Debian also has more control if a site maintainer goes MIA. More info: https://wiki.debian.org/Teams/DebianNet You might notice some Openstack mentioned there, we had some intention to set up a Debian cloud for hosting these things, that could also be used for other additional Debiany things like archive rebuilds, but these have so far fallen through. We still consider it a good idea and hopefully it will work out some other time (if you're a large company who can sponsor few racks and servers, please get in touch!) DebConf22 and Debian 12 era DebConf22 was the first time we returned to an in-person DebConf. It was a bit smaller than our usual DebConf - understandably so, considering that there were still COVID risks and people who were at high risk or who had family with high risk factors did the sensible thing and stayed home. After watching many MiniDebConfs online, I also attended my first ever MiniDebConf in Hamburg. It still feels odd typing that, it feels like I should've been at one before, but my location makes attending them difficult (on a side-note, a few of us are working on bootstrapping a South African Debian community and hopefully we can pull off MiniDebConf in South Africa later this year). While I was at the MiniDebConf, I gave a talk where I covered the evolution of firmware, from the simple e-proms that you'd find in old printers to the complicated firmware in modern GPUs that basically contain complete operating systems- complete with drivers for the device their running on. I also showed my shiny new laptop, and explained that it's impossible to install that laptop without non-free firmware (you'd get a black display on d-i or Debian live). Also that you couldn't even use an accessibility mode with audio since even that depends on non-free firmware these days. Steve, from the image building team, has said for a while that we need to do a GR to vote for this, and after more discussion at DebConf, I kept nudging him to propose the GR, and we ended up voting in favour of it. I do believe that someone out there should be campaigning for more free firmware (unfortunately in Debian we just don't have the resources for this), but, I'm glad that we have the firmware included. In the end, the choice comes down to whether we still want Debian to be installable on mainstream bare-metal hardware. At this point, I'd like to give a special thanks to the ftpmasters, image building team and the installer team who worked really hard to get the changes done that were needed in order to make this happen for Debian 12, and for being really proactive for remaining niggles that was solved by the time Debian 12.1 was released. The included firmware contributed to Debian 12 being a huge success, but it wasn't the only factor. I had a list of personal peeves, and as the hard freeze hit, I lost hope that these would be fixed and made peace with the fact that Debian 12 would release with those bugs. I'm glad that lots of people proved me wrong and also proved that it's never to late to fix bugs, everything on my list got eliminated by the time final freeze hit, which was great! We usually aim to have a release ready about 2 years after the previous release, sometimes there are complications during a freeze and it can take a bit longer. But due to the excellent co-ordination of the release team and heavy lifting from many DDs, the Debian 12 release happened 21 months and 3 weeks after the Debian 11 release. I hope the work from the release team continues to pay off so that we can achieve their goals of having shorter and less painful freezes in the future! Even though many things were going well, the ongoing usr-merge effort highlighted some social problems within our processes. I started typing out the whole history of usrmerge here, but it's going to be too long for the purpose of this mail. Important questions that did come out of this is, should core Debian packages be team maintained? And also about how far the CTTE should really be able to override a maintainer. We had lots of discussion about this at DebConf22, but didn't make much concrete progress. I think that at some point we'll probably have a GR about package maintenance. Also, thank you to Guillem who very patiently explained a few things to me (after probably having have to done so many times to others before already) and to Helmut who have done the same during the MiniDebConf in Hamburg. I think all the technical and social issues here are fixable, it will just take some time and patience and I have lots of confidence in everyone involved. UsrMerge wiki page: https://wiki.debian.org/UsrMerge DebConf 23 and Debian 13 era DebConf23 took place in Kochi, India. At the end of my Bits from the DPL talk there, someone asked me what the most difficult thing I had to do was during my terms as DPL. I answered that nothing particular stood out, and even the most difficult tasks ended up being rewarding to work on. Little did I know that my most difficult period of being DPL was just about to follow. During the day trip, one of our contributors, Abraham Raji, passed away in a tragic accident. There's really not anything anyone could've done to predict or stop it, but it was devastating to many of us, especially the people closest to him. Quite a number of DebConf attendees went to his funeral, wearing the DebConf t-shirts he designed as a tribute. It still haunts me when I saw his mother scream "He was my everything! He was my everything!", this was by a large margin the hardest day I've ever had in Debian, and I really wasn't ok for even a few weeks after that and I think the hurt will be with many of us for some time to come. So, a plea again to everyone, please take care of yourself! There's probably more people that love you than you realise. A special thanks to the DebConf23 team, who did a really good job despite all the uphills they faced (and there were many!). As DPL, I think that planning for a DebConf is near to impossible, all you can do is show up and just jump into things. I planned to work with Enrico to finish up something that will hopefully save future DPLs some time, and that is a web-based DD certificate creator instead of having the DPL do so manually using LaTeX. It already mostly works, you can see the work so far by visiting
https://nm.debian.org/person/ACCOUNTNAME/certificate/ and replacing
ACCOUNTNAME with your Debian account name, and if you're a DD, you
should see your certificate. It still needs a few minor changes and a
DPL signature, but at this point I think that will be finished up when
the new DPL start. Thanks to Enrico for working on this!
Since my first term, I've been trying to find ways to improve all our
accounting/finance issues. Tracking what we spend on things, and
getting an annual overview is hard, especially over 3 trusted
organisations. The reimbursement process can also be really tedious,
especially when you have to provide files in a certain order and
combine them into a PDF. So, at DebConf22 we had a meeting along with
the treasurer team and Stefano Rivera who said that it might be
possible for him to work on a new system as part of his Freexian work.
It worked out, and Freexian funded the development of the system since
then, and after DebConf23 we handled the reimbursements for the
conference via the new reimbursements site:
https://reimbursements.debian.net/
It's still early days, but over time it should be linked to all our TOs
and we'll use the same category codes across the board. So, overall,
our reimbursement process becomes a lot simpler, and also we'll be able
to get information like how much money we've spent on any category in
any period. It will also help us to track how much money we have
available or how much we spend on recurring costs. Right now that needs
manual polling from our TOs. So I'm really glad that this is a big
long-standing problem in the project that is being fixed.
For Debian 13, we're waving goodbye to the KFreeBSD and mipsel ports.
But we're also gaining riscv64 and loongarch64 as release
architectures! I have 3 different RISC-V based machines on my desk here
that I haven't had much time to work with yet, you can expect some blog
posts about them soon after my DPL term ends!
As Debian is a unix-like system, we're affected by the
Year 2038 problem, where systems that uses 32 bit time in seconds
since 1970 run out of available time and will wrap back to 1970 or have
other undefined behaviour. A detailed wiki page explains how this
works in Debian, and currently we're going through a rather large
transition to make this possible.
I believe this is the right time for Debian to be addressing this,
we're still a bit more than a year away for the Debian 13 release, and
this provides enough time to test the implementation before 2038 rolls
along.
Of course, big complicated transitions with dependency loops that
causes chaos for everyone would still be too easy, so this past weekend
(which is a holiday period in most of the west due to Easter weekend)
has been filled with dealing with an upstream bug in xz-utils, where a
backdoor was placed in this key piece of software. An Ars Technica
covers it quite well, so I won't go into all the details here. I
mention it because I want to give yet another special thanks to
everyone involved in dealing with this on the Debian side. Everyone
involved, from the ftpmasters to security team and others involved were
super calm and professional and made quick, high quality decisions.
This also lead to the archive being frozen on Saturday, this is the
first time I've seen this happen since I've been a DD, but I'm sure
next week will go better!
Looking forward
It's really been an honour for me to serve as DPL. It might well be my
biggest achievement in my life. Previous DPLs range from prominent
software engineers to game developers, or people who have done things
like complete Iron Man, run other huge open source projects and are
part of big consortiums. Ian Jackson even authored dpkg and is now
working on the very interesting tag2upload service!
I'm a relative nobody, just someone who grew up as a poor kid in South
Africa, who just really cares about Debian a lot. And, above all, I'm
really thankful that I didn't do anything major to screw up Debian for
good.
Not unlike learning how to use Debian, and also becoming a Debian
Developer, I've learned a lot from this and it's been a really valuable
growth experience for me.
I know I can't possible give all the thanks to everyone who deserves
it, so here's a big big thanks to everyone who have worked so hard and
who have put in many, many hours to making Debian better, I consider
you all heroes!
-Jonathan
apt install rustc cargo. Either do that and make sure to use only Rust libraries from your distro (with the tiresome config runes below); or, just use rustup.
curl bash
curl bash bullet
apt install rustc cargo, you will end up using Debian s compiler but upstream libraries, directly and uncurated from crates.io.
This is not what you want. There are about two reasonable things to do, depending on your preferences.
Q. Download and run whatever code from the internet?
The key question is this:
Are you comfortable downloading code, directly from hundreds of upstream Rust package maintainers, and running it ?
That s what cargo does. It s one of the main things it s for. Debian s cargo behaves, in this respect, just like upstream s. Let me say that again:
Debian s cargo promiscuously downloads code from crates.io just like upstream cargo.
So if you use Debian s cargo in the most obvious way, you are still downloading and running all those random libraries. The only thing you re avoiding downloading is the Rust compiler itself, which is precisely the part that is most carefully maintained, and of least concern.
Debian s cargo can even download from crates.io when you re building official Debian source packages written in Rust: if you run dpkg-buildpackage, the downloading is suppressed; but a plain cargo build will try to obtain and use dependencies from the upstream ecosystem. ( Happily , if you do this, it s quite likely to bail out early due to version mismatches, before actually downloading anything.)
Option 1: WTF, no I don t want curl bash
OK, but then you must limit yourself to libraries available within Debian. Each Debian release provides a curated set. It may or may not be sufficient for your needs. Many capable programs can be written using the packages in Debian.
But any upstream Rust project that you encounter is likely to be a pain to get working, unless their maintainers specifically intend to support this. (This is fairly rare, and the Rust tooling doesn t make it easy.)
To go with this plan, apt install rustc cargo and put this in your configuration, in $HOME/.cargo/config.toml:
[source.debian-packages]
directory = "/usr/share/cargo/registry"
[source.crates-io]
replace-with = "debian-packages"/usr/share for dependencies, rather than downloading them from crates.io. You must then install the librust-FOO-dev packages for each of your dependencies, with apt.
This will allow you to write your own program in Rust, and build it using cargo build.
Option 2: Biting the curl bash bullet
If you want to build software that isn t specifically targeted at Debian s Rust you will probably need to use packages from crates.io, not from Debian.
If you re doing to do that, there is little point not using rustup to get the latest compiler. rustup s install rune is alarming, but cargo will be doing exactly the same kind of thing, only worse (because it trusts many more people) and more hidden.
So in this case: do run the curl bash install rune.
Hopefully the Rust project you are trying to build have shipped a Cargo.lock; that contains hashes of all the dependencies that they last used and tested. If you run cargo build --locked, cargo will only use those versions, which are hopefully OK.
And you can run cargo audit to see if there are any reported vulnerabilities or problems. But you ll have to bootstrap this with cargo install --locked cargo-audit; cargo-audit is from the RUSTSEC folks who do care about these kind of things, so hopefully running their code (and their dependencies) is fine. Note the --locked which is needed because cargo s default behaviour is wrong.
Privilege separation
This approach is rather alarming. For my personal use, I wrote a privsep tool which allows me to run all this upstream Rust code as a separate user.
That tool is nailing-cargo. It s not particularly well productised, or tested, but it does work for at least one person besides me. You may wish to try it out, or consider alternative arrangements. Bug reports and patches welcome.
OMG what a mess
Indeed. There are large number of technical and social factors at play.
cargo itself is deeply troubling, both in principle, and in detail. I often find myself severely disappointed with its maintainers decisions. In mitigation, much of the wider Rust upstream community does takes this kind of thing very seriously, and often makes good choices. RUSTSEC is one of the results.
Debian s technical arrangements for Rust packaging are quite dysfunctional, too: IMO the scheme is based on fundamentally wrong design principles. But, the Debian Rust packaging team is dynamic, constantly working the update treadmills; and the team is generally welcoming and helpful.
Sadly last time I explored the possibility, the Debian Rust Team didn t have the appetite for more fundamental changes to the workflow (including, for example, changes to dependency version handling). Significant improvements to upstream cargo s approach seem unlikely, too; we can only hope that eventually someone might manage to supplant it.
edited 2024-03-21 21:49 to add a cut tagThe clearance was entered initially with estimated import charges of 400.03, consisting of 387.83 VAT, and 12.20 disbursement fee. This original entry regrettably did not include the freight cost for calculating the VAT, and as such when submitted for final entry the VAT value was adjusted to include this and an amended invoice was issued for an additional 39.84. HMRC calculate the amount against which VAT is raised using the value of goods, insurance and freight, however they also may apply a VAT adjustment figure. The VAT Adjustment is based on many factors (Incidental costs in regards to a shipment), which includes charge for currency conversion if the invoice does not list values in Sterling, but the main is due to the inland freight from airport of destination to the final delivery point, as this charge varies, for example, from EMA to Edinburgh would be 150, from EMA to Derby would be 1, so each year UPS must supply HMRC with all values incurred for entry build up and they give an average which UPS have to use on the entry build up as the VAT Adjustment. The correct calculation for the import charges is therefore as follows: Goods value divided by exchange rate 2,489.53 EUR / 1.1683 = 2,130.89 GBP Duty: Goods value plus freight (%) 2,130.89 GBP + 5% = 2,237.43 GBP. That total times the duty rate. X 0 % = 0 GBP VAT: Goods value plus freight (100%) 2,130.89 GBP + 0 = 2,130.89 GBP That total plus duty and VAT adjustment 2,130.89 GBP + 0 GBP + 7.49 GBP = 2,348.08 GBP. That total times 20% VAT = 427.67 GBP As detailed above we must confirm that the final VAT charges applied to the shipment were correct, and that no refund of this is therefore due.This looks very like HMRC-originated nonsense. If only they had put it on the original bills! It s completely ridiculous that it took four months and near-litigation to obtain it. Disbursement fee One more thing. UPS billed me a 12 disbursement fee . When you import something, there s often tax to pay. The courier company pays that to the government, and the consignee pays it to the courier. Usually the courier demands it before final delivery, since otherwise they end up having to chase it as a debt. It is common for parcel companies to add a random fee of their own. As I note in my Particulars, there isn t any legal basis for this. In my own offer of settlement I proposed that UPS should:
State under what principle of English law (such as, what enactment or principle of Common Law), you levy the disbursement fee (or refund it).To my surprise they actually responded to this in their own settlement letter. (They didn t, for example, mention the harassment at all.) They said (emphasis mine):
A disbursement fee is a fee for amounts paid or processed on behalf of a client. It is an established category of charge used by legal firms, amongst other companies, for billing of various ancillary costs which may be incurred in completion of service. Disbursement fees are not covered by a specific law, nor are they legally prohibited. Regarding UPS disbursement fee this is an administrative charge levied for the use of UPS deferment account to prepay import charges for clearance through CDS. This charge would therefore be billed to the party that is responsible for the import charges, normally the consignee or receiver of the shipment in question. The disbursement fee as applied is legitimate, and as you have stated is a commonly used and recognised charge throughout the courier industry, and I can confirm that this was charged correctly in this instance.On UPS s analysis, they can just make up whatever fee they like. That is clearly not right (and I don t even need to refer to consumer protection law, which would also make it obviously unlawful). And, that everyone does it doesn t make it lawful. There are so many things that are ubiquitous but unlawful, especially nowadays when much of the legal system - especially consumer protection regulators - has been underfunded to beyond the point of collapse. Next time this comes up I might have a go at getting the fee back. (Obviously I ll have to pay it first, to get my parcel.) ParcelForce and Royal Mail I think this analysis doesn t apply to ParcelForce and (probably) Royal Mail. I looked into this in 2009, and I found that Parcelforce had been given the ability to write their own private laws: Schemes made under section 89 of the Postal Services Act 2000. This is obviously ridiculous but I think it was the law in 2009. I doubt the intervening governments have fixed it. Furniture Oh, yes, the actual furniture. The replacements arrived intact and are great :-).
debci was initially announced on that month's Misc
Developer News, and later uploaded to Debian. It's been
continuously developed for the last 10 years, evolved from a single shell
script running tests in a loop into a distributed system with 47
geographically-distributed machines as of writing this piece, became part of
the official Debian release process gating migrations to testing, had 5 Summer
of Code and Outrechy interns working on it, and processed beyond 40 million
test runs.
In there years, Debian CI has received contributions from a lot of people, but
I would like to give special credits to the following:
apt source, or dpkg-source. Instead, use dgit and work in git.
Also, don t use: VCS links on official Debian web pages, debcheckout, or Debian s (semi-)official gitlab, Salsa. These are suitable for Debian experts only; for most people they can be beartraps. Instead, use dgit.
>
Struggling with Debian source packages?
A friend of mine recently asked for help on IRC. They re an experienced Debian administrator and user, and were trying to: make a change to a Debian package; build and install and run binary packages from it; and record that change for their future self, and their colleagues. They ended up trying to comprehend quilt.
quilt is an ancient utility for managing sets of source code patches, from well before the era of modern version control. It has many strange behaviours and footguns. Debian s ancient and obsolete tarballs-and-patches source package format (which I designed the initial version of in 1993) nowadays uses quilt, at least for most packages.
You don t want to deal with any of this nonsense. You don t want to learn quilt, and suffer its misbehaviours. You don t want to learn about Debian source packages and wrestle dpkg-source.
Happily, you don t need to.
Just use dgit
One of dgit s main objectives is to minimise the amount of Debian craziness you need to learn. dgit aims to empower you to make changes to the software you re running, conveniently and with a minimum of fuss.
You can use dgit to get the source code to a Debian package, as a git tree, with dgit clone (and dgit fetch). The git tree can be made into a binary package directly.
The only things you really need to know are:
dgit clone PACKAGE bookworm,-security (yes, with a comma).
debian/changelog to make your packages have a different version number.
dpkg-buildpackage -uc -b.
debian/rules clean can be inadequate, or crazy. Always commit before building, and use git clean and git reset --hard instead of running clean rules from the package.
dpkg-source manual!) Instead, to preserve and share your work, use the git branch.
dgit pull or dgit fetch can be used to get updates.
There is a more comprehensive tutorial, with example runes, in the dgit-user(7) manpage. (There is of course complete reference documentation, but you don t need to bother reading it.)
Objections
But I don t want to learn yet another tool
One of dgit s main goals is to save people from learning things you don t need to. It aims to be straightforward, convenient, and (so far as Debian permits) unsurprising.
So: don t learn dgit. Just run it and it will be fine :-).
Shouldn t I be using official Debian git repos?
Absolutely not.
Unless you are a Debian expert, these can be terrible beartraps. One possible outcome is that you might build an apparently working program but without the security patches. Yikes!
I discussed this in more detail in 2021 in another blog post plugging dgit.
Gosh, is Debian really this bad?
Yes. On behalf of the Debian Project, I apologise.
Debian is a very conservative institution. Change usually comes very slowly. (And when rapid or radical change has been forced through, the results haven t always been pretty, either technically or socially.)
Sadly this means that sometimes much needed change can take a very long time, if it happens at all. But this tendency also provides the stability and reliability that people have come to rely on Debian for.
I m a Debian maintainer. You tell me dgit is something totally different!
dgit is, in fact, a general bidirectional gateway between the Debian archive and git.
So yes, dgit is also a tool for Debian uploaders. You should use it to do your uploads, whenever you can. It s more convenient and more reliable than git-buildpackage and dput runes, and produces better output for users. You too can start to forget how to deal with source packages!
A full treatment of this is beyond the scope of this blog post.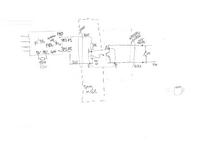
 (click for diagram scans as pdfs).
The DigiSpark has just a USB tongue, which is very wobbly in a normal USB socket. I designed a 3D printed case which also had an approximation of the rest of the USB A plug. The plug is out of spec; our printer won t go fine enough - and anyway, the shield is supposed to be metal, not fragile plastic. But it fit in the USB PSU I was using, satisfactorily if a bit stiffly, and also into the connector for programming via my laptop.
Inside the coffee machine, there s the boundary between the original, coupled to mains, UI board, and the isolated low voltage of the microcontroller. I used a reasonably substantial cable to bring out the low voltage connection, past all the other hazardous innards, to make sure it stays isolated.
I added a drain power supply resistor on another of the GPIOs. This is enabled, with a draw of about 30mA, when the microcontroller is soon going to off / on cycle the coffee machine. That reduces the risk that the user will turn off the smart plug, and turn off the machine, but that the microcontroller turns the coffee machine back on again using the remaining power from USB PSU. Empirically in my setup it reduces the time from smart plug off to microcontroller stops from about 2-3s to more like 1s.
Optoisolator board (inside coffee machine) pictures
(Click through for full size images.)
(click for diagram scans as pdfs).
The DigiSpark has just a USB tongue, which is very wobbly in a normal USB socket. I designed a 3D printed case which also had an approximation of the rest of the USB A plug. The plug is out of spec; our printer won t go fine enough - and anyway, the shield is supposed to be metal, not fragile plastic. But it fit in the USB PSU I was using, satisfactorily if a bit stiffly, and also into the connector for programming via my laptop.
Inside the coffee machine, there s the boundary between the original, coupled to mains, UI board, and the isolated low voltage of the microcontroller. I used a reasonably substantial cable to bring out the low voltage connection, past all the other hazardous innards, to make sure it stays isolated.
I added a drain power supply resistor on another of the GPIOs. This is enabled, with a draw of about 30mA, when the microcontroller is soon going to off / on cycle the coffee machine. That reduces the risk that the user will turn off the smart plug, and turn off the machine, but that the microcontroller turns the coffee machine back on again using the remaining power from USB PSU. Empirically in my setup it reduces the time from smart plug off to microcontroller stops from about 2-3s to more like 1s.
Optoisolator board (inside coffee machine) pictures
(Click through for full size images.)


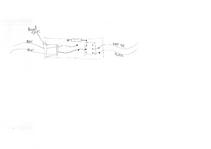
 Microcontroller board (in USB-plug-ish housing) pictures
Microcontroller board (in USB-plug-ish housing) pictures


 Implementation - software
I originally used the Arduino IDE, writing my program in C. I had a bad time with that and rewrote it in Rust.
The firmware is in a repository on Debian s gitlab
Results
I can now cause the coffee to start, from my phone. It can be programmed more than 12h in advance. And it stays warm until we ve drunk it.
UI is worse
There s one aspect of the original Morphy Richards machine that I haven t improved: the user interface is still poor. Indeed, it s now even worse:
To turn the machine on, you probably want to turn on the smart plug instead. Unhappily, the power button for that is invisible in its installed location.
In particular, in the usual case, if you want to turn it off, you should ideally turn off both the smart plug (which can be done with the button on it) and the coffee machine itself. If you forget to turn off the smart plug, the machine can end up being turned on, very briefly, a handful of times, over the next hour or two.
Epilogue
We had used the new features a handful of times when one morning the coffee machine just wouldn t make coffee. The UI showed it turning on, but it wouldn t get hot, so no coffee. I thought oh no, I ve broken it!
But, on investigation, I found that the machine s heating element was open circuit (ie, completely broken). I didn t mess with that part. So, hooray! Not my fault. Probably, just being inverted a number of times and generally lightly jostled, had precipitated a latent fault. The machine was a number of years old.
Happily I found a replacement, identical, machine, online. I ve transplanted my modification and now it all works well.
Bonus pictures
(Click through for full size images.)
Implementation - software
I originally used the Arduino IDE, writing my program in C. I had a bad time with that and rewrote it in Rust.
The firmware is in a repository on Debian s gitlab
Results
I can now cause the coffee to start, from my phone. It can be programmed more than 12h in advance. And it stays warm until we ve drunk it.
UI is worse
There s one aspect of the original Morphy Richards machine that I haven t improved: the user interface is still poor. Indeed, it s now even worse:
To turn the machine on, you probably want to turn on the smart plug instead. Unhappily, the power button for that is invisible in its installed location.
In particular, in the usual case, if you want to turn it off, you should ideally turn off both the smart plug (which can be done with the button on it) and the coffee machine itself. If you forget to turn off the smart plug, the machine can end up being turned on, very briefly, a handful of times, over the next hour or two.
Epilogue
We had used the new features a handful of times when one morning the coffee machine just wouldn t make coffee. The UI showed it turning on, but it wouldn t get hot, so no coffee. I thought oh no, I ve broken it!
But, on investigation, I found that the machine s heating element was open circuit (ie, completely broken). I didn t mess with that part. So, hooray! Not my fault. Probably, just being inverted a number of times and generally lightly jostled, had precipitated a latent fault. The machine was a number of years old.
Happily I found a replacement, identical, machine, online. I ve transplanted my modification and now it all works well.
Bonus pictures
(Click through for full size images.)

 edited 2023-11-26 14:59 UTC in an attempt to fix TOC links
edited 2023-11-26 14:59 UTC in an attempt to fix TOC linksarduino was in Debian.
But it turns out that the Debian package s version doesn t support the DigiSpark. (AFAICT from the list it offered me, I m not sure it supports any ATTiny85 board.) Also, disturbingly, its board manager seemed to be offering to install board support, suggesting it would download stuff from the internet and run it. That wouldn t be acceptable for my main laptop.
I didn t expect to be doing much programming or debugging, and the project didn t have significant security requirements: the chip, in my circuit, has only a very narrow ability do anything to the real world, and no network connection of any kind. So I thought it would be tolerable to do the project on my low-security video laptop . That s the machine where I m prepared to say yes to installing random software off the internet.
So I went to the upstream Arduino site and downloaded a tarball containing the Arduino IDE. After unpacking that in /opt it ran and produced a pointy-clicky IDE, as expected. I had already found a 3rd-party tutorial saying I needed to add a magic URL (from the DigiSpark s vendor) in the preferences. That indeed allowed it to download a whole pile of stuff. Compilers, bootloader clients, god knows what.
However, my tiny test program didn t make it to the board. Half-buried in a too-small window was an error message about the board s bootloader ( Micronucleus ) being too new.
The boards I had came pre-flashed with micronucleus 2.2. Which is hardly new, But even so the official Arduino IDE (or maybe the DigiSpark s board package?) still contains an old version. So now we have all the downsides of curl bash-ware, but we re lacking the it s up to date and it just works upsides.
Further digging found some random forum posts which suggested simply downloading a newer micronucleus and manually stuffing it into the right place: one overwrites a specific file, in the middle the heaps of stuff that the Arduino IDE s board support downloader squirrels away in your home directory. (In my case, the home directory of the untrusted shared user on the video laptop,)
So, whatever . I did that. And it worked!
Having demo d my ability to run code on the board, I set about writing my program.
Writing C again
The programming language offered via the Arduino IDE is C.
It s been a little while since I started a new thing in C. After having spent so much of the last several years writing Rust. C s primitiveness quickly started to grate, and the program couldn t easily be as DRY as I wanted (Don t Repeat Yourself, see Wilson et al, 2012, 4, p.6). But, I carried on; after all, this was going to be quite a small job.
Soon enough I had a program that looked right and compiled.
Before testing it in circuit, I wanted to do some QA. So I wrote a simulator harness that #included my Arduino source file, and provided imitations of the few Arduino library calls my program used. As an side advantage, I could build and run the simulation on my main machine, in my normal development environment (Emacs, make, etc.). The simulator runs confirmed the correct behaviour. (Perhaps there would have been some more faithful simulation tool, but the Arduino IDE didn t seem to offer it, and I wasn t inclined to go further down that kind of path.)
So I got the video laptop out, and used the Arduino IDE to flash the program. It didn t run properly. It hung almost immediately. Some very ad-hoc debugging via led-blinking (like printf debugging, only much worse) convinced me that my problem was as follows:
Arduino C has 16-bit ints. My test harness was on my 64-bit Linux machine. C was autoconverting things (when building for the micrcocontroller). The way the Arduino IDE ran the compiler didn t pass the warning options necessary to spot narrowing implicit conversions. Those warnings aren t the default in C in general javax.jmdns, with hex DNS packet dumps. WTF.
Other things that were vexing about the Arduino IDE: it has fairly fixed notions (which don t seem to be documented) about how your files and directories ought to be laid out, and magical machinery for finding things you put nearby its sketch (as it calls them) and sticking them in its ear, causing lossage. It has a tendency to become confused if you edit files under its feet (e.g. with git checkout). It wasn t really very suited to a workflow where principal development occurs elsewhere.
And, important settings such as the project s clock speed, or even the target board, or the compiler warning settings to use weren t stored in the project directory along with the actual code. I didn t look too hard, but I presume they must be in a dotfile somewhere. This is madness.
Apparently there is an Arduino CLI too. But I was already quite exasperated, and I didn t like the idea of going so far off the beaten path, when the whole point of using all this was to stay with popular tooling and share fate with others. (How do these others cope? I have no idea.)
As for the integer overflow bug:
I didn t seriously consider trying to figure out how to control in detail the C compiler options passed by the Arduino IDE. (Perhaps this is possible, but not really documented?) I did consider trying to run a cross-compiler myself from the command line, with appropriate warning options, but that would have involved providing (or stubbing, again) the Arduino/DigiSpark libraries (and bugs could easily lurk at that interface).
Instead, I thought, if only I had written the thing in Rust . But that wasn t possible, was it? Does Rust even support this board?
Rust on the DigiSpark
I did a cursory web search and found a very useful blog post by Dylan Garrett.
This encouraged me to think it might be a workable strategy. I looked at the instructions there. It seemed like I could run them via the privsep arrangement I use to protect myself when developing using upstream cargo packages from crates.io.
I got surprisingly far surprisingly quickly. It did, rather startlingly, cause my rustup to download a random recent Nightly Rust, but I have six of those already for other Reasons. Very quickly I got the trinket LED blink example, referenced by Dylan s blog post, to compile. Manually copying the file to the video laptop allowed me to run the previously-downloaded micronucleus executable and successfully run the blink example on my board!
I thought a more principled approach to the bootloader client might allow a more convenient workflow. I found the upstream Micronucleus git releases and tags, and had a look over its source code, release dates, etc. It seemed plausible, so I compiled v2.6 from source. That was a success: now I could build and install a Rust program onto my board, from the command line, on my main machine. No more pratting about with the video laptop.
I had got further, more quickly, with Rust, than with the Arduino IDE, and the outcome and workflow was superior.
So, basking in my success, I copied the directory containing the example into my own project, renamed it, and adjusted the path references.
That didn t work. Now it didn t build. Even after I copied about .cargo/config.toml and rust-toolchain.toml it didn t build, producing a variety of exciting messages, depending what precisely I tried. I don t have detailed logs of my flailing: the instructions say to build it by cd ing to the subdirectory, and, given that what I was trying to do was to not follow those instructions, it didn t seem sensible to try to prepare a proper repro so I could file a ticket. I wasn t optimistic about investigating it more deeply myself: I have some experience of fighting cargo, and it s not usually fun. Looking at some of the build control files, things seemed quite complicated.
Additionally, not all of the crates are on crates.io. I have no idea why not. So, I would need to supply local copies of them anyway. I decided to just git subtree add the avr-hal git tree.
(That seemed better than the approach taken by the avr-hal project s cargo template, since that template involve a cargo dependency on a foreign git repository. Perhaps it would be possible to turn them into path dependencies, but given that I had evidence of file-location-sensitive behaviour, which I didn t feel like I wanted to spend time investigating, using that seems like it would possibly have invited more trouble. Also, I don t like package templates very much. They re a form of clone-and-hack: you end up stuck with whatever bugs or oddities exist in the version of the template which was current when you started.)
Since I couldn t get things to build outside avr-hal, I edited the example, within avr-hal, to refer to my (one) program.rs file outside avr-hal, with a #[path] instruction. That s not pretty, but it worked.
I also had to write a nasty shell script to work around the lack of good support in my nailing-cargo privsep tool for builds where cargo must be invoked in a deep subdirectory, and/or Cargo.lock isn t where it expects, and/or the target directory containing build products is in a weird place. It also has to filter the output from cargo to adjust the pathnames in the error messages. Otherwise, running both cd A; cargo build and cd B; cargo build from a Makefile produces confusing sets of error messages, some of which contain filenames relative to A and some relative to B, making it impossible for my Emacs to reliably find the right file.
RIIR (Rewrite It In Rust)
Having got my build tooling sorted out I could go back to my actual program.
I translated the main program, and the simulator, from C to Rust, more or less line-by-line. I made the Rust version of the simulator produce the same output format as the C one. That let me check that the two programs had the same (simulated) behaviour. Which they did (after fixing a few glitches in the simulator log formatting).
Emboldened, I flashed the Rust version of my program to the DigiSpark. It worked right away!
RIIR had caused the bug to vanish. Of course, to rewrite the program in Rust, and get it to compile, it was necessary to be careful about the types of all the various integers, so that s not so surprising. Indeed, it was the point. I was then able to refactor the program to be a bit more natural and DRY, and improve some internal interfaces. Rust s greater power, compared to C, made those cleanups easier, so making them worthwhile.
However, when doing real-world testing I found a weird problem: my timings were off. Measured, the real program was too fast by a factor of slightly more than 2. A bit of searching (and searching my memory) revealed the cause: I was using a board template for an Adafruit Trinket. The Trinket has a clock speed of 8MHz. But the DigiSpark runs at 16.5MHz. (This is discussed in a ticket against one of the C/C++ libraries supporting the ATTiny85 chip.)
The Arduino IDE had offered me a choice of clock speeds. I have no idea how that dropdown menu took effect; I suspect it was adding prelude code to adjust the clock prescaler. But my attempts to mess with the CPU clock prescaler register by hand at the start of my Rust program didn t bear fruit.
So instead, I adopted a bodge: since my code has (for code structure reasons, amongst others) only one place where it dealt with the underlying hardware s notion of time, I simply changed my delay function to adjust the passed-in delay values, compensating for the wrong clock speed.
There was probably a more principled way. For example I could have (re)based my work on either of the two unmerged open MRs which added proper support for the DigiSpark board, rather than abusing the Adafruit Trinket definition. But, having a nearly-working setup, and an explanation for the behaviour, I preferred the narrower fix to reopening any cans of worms.
An offer of help
As will be obvious from this posting, I m not an expert in dev tools for embedded systems. Far from it. This area seems like quite a deep swamp, and I m probably not the person to help drain it. (Frankly, much of the improvement work ought to be done, and paid for, by hardware vendors.)
But, as a full Member of the Debian Project, I have considerable gatekeeping authority there. I also have much experience of software packaging, build systems, and release management. If anyone wants to try to improve the situation with embedded tooling in Debian, and is willing to do the actual packaging work. I would be happy to advise, and to review and sponsor your contributions.
An obvious candidate: it seems to me that micronucleus could easily be in Debian. Possibly a DigiSpark board definition could be provided to go with the arduino package.
Unfortunately, IMO Debian s Rust packaging tooling and workflows are very poor, and the first of my suggestions for improvement wasn t well received. So if you need help with improving Rust packages in Debian, please talk to the Debian Rust Team yourself.
Conclusions
Embedded programming is still rather a mess and probably always will be.
Embedded build systems can be bizarre. Documentation is scant. You re often expected to download board support packages full of mystery binaries, from the board vendor (or others).
Dev tooling is maddening, especially if aimed at novice programmers. You want version control? Hermetic tracking of your project s build and install configuration? Actually to be told by the compiler when you write obvious bugs? You re way off the beaten track.
As ever, Free Software is under-resourced and the maintainers are often busy, or (reasonably) have other things to do with their lives.
All is not lost
Rust can be a significantly better bet than C for embedded software:
The Rust compiler will catch a good proportion of programming errors, and an experienced Rust programmer can arrange (by suitable internal architecture) to catch nearly all of them. When writing for a chip in the middle of some circuit, where debugging involves staring an LED or a multimeter, that s precisely what you want.
Rust embedded dev tooling was, in this case, considerably better. Still quite chaotic and strange, and less mature, perhaps. But: significantly fewer mystery downloads, and significantly less crazy deviations from the language s normal build system. Overall, less bad software supply chain integrity.
The ATTiny85 chip, and the DigiSpark board, served my hardware needs very well. (More about the hardware aspects of this project in a future posting.)DKIM-Signature header then the message is DKIM signed. If they don t, then it wasn t. Most email traversing the public internet is DKIM signed nowadays; so if they don t see the header probably they re not looking using the right tools, or they re actually on the same email system as you.
In messages signed by a system running dkim-rotate, there will also be a header about the key rotation, to notify potential verifiers of the situation. Other systems that avoid non-repudiation-through-DKIM might do something similar. dkim-rotate s header looks like this:
DKIM-Signature-Warning: NOTE REGARDING DKIM KEY COMPROMISE
https://www.chiark.greenend.org.uk/dkim-rotate/README.txt
https://www.chiark.greenend.org.uk/dkim-rotate/ae/aeb689c2066c5b3fee673355309fe1c7.pem # save the message as test-email.mbox
apt install libmail-dkim-perl # or equivalent on another distro
dkimproxy-verify <test-email.mbox originator address: ijackson@chiark.greenend.org.uk
signature identity: @chiark.greenend.org.uk
verify result: pass
...verify result: fail (body has been altered) then probably your friend didn t manage to faithfully save the unalterered raw message.
Checking old emails cannot be verified
When you both have that working, have your friend find an older email of yours, from (say) month ago. Perform the same steps.
Hopefully they will see something like this:
originator address: ijackson@chiark.greenend.org.uk
signature identity: @chiark.greenend.org.uk
verify result: fail (bad RSA signature) verify result: invalid (public key: not available)verify result: pass, then they have verified that that old email of yours is genuine. Anyone who had a copy of the mail can do that. This is good for email thieves, but not for you.
For email admins: announcing dkim-rotate 1.0
I have been running dkim-rotate 0.4 on my infrastructure, since last August. and I had entirely forgotten about it: it has run flawlessly for a year. I was reminded of the topic by seeing DKIM in other blog posts. Obviously, it is time to decreee that dkim-rotate is 1.0.
If you re a mail system administrator, your users are best served if you use something like dkim-rotate. The package is available in Debian stable, and supports Exim out of the box, but other MTAs should be easy to support too, via some simple ad-hoc scripting.
Limitation of this approach
Even with this key rotation approach, emails remain nonrepudiable for a short period after they re sent - typically, a few days.
Someone who obtains a leaked email very promptly, and shows it to the journalist (for example) right away, can still convince the journalist. This is not great, but at least it doesn t apply to the vast bulk of your email archive.
There are possible email protocol improvements which might help, but they re quite out of scope for this article.
Edited 2023-10-01 00:20 +01:00 to fix some grammar Edited 2023-09-01 00:58 +01:00 to fix the link to the Debconf policy.
Edited 2023-09-01 00:58 +01:00 to fix the link to the Debconf policy.place tag, any part of which was within my ambit. That included some places that probably oughtn t to have counted, but, fine.
I also decided that I wouldn t visit suburbs of Cambridge, separately from Cambridge itself. I don t consider them separate settlements, at least, not if they re conurbated with Cambridge. So that excluded Trumpington, for example. But I decided that Girton and Fen Ditton were (just) separable. Although the place where I consider Girton and Cambridge to nearly touch, is administratively well inside Girton, I chose to look at land use (on the ground, and in OSM data), rather than administrative boundaries.
But I did visit both Histon and Impington, and all each of the Shelfords and Stapleford, as separate entries in my list. Mostly because otherwise I d have to decide whether to skip (say) Impington, or Histon. Whereas skipping suburbs of Cambridge in favour of Cambridge itself was an easy decision, and it also got rid of a bunch of what would have been quite short, boring, urban expeditions.
I sorted all the Greats and Littles under G and L, rather than (say) Shelford, Great , which seemed like it would be cheating because then I would be able to do Shelford, Great and Shelford, Little in one go.
Northstowe turned from mostly a building site into something that was arguably a settlement, during my project. It wasn t included in the output of my original data mining. Of course it s conurbated with Oakington - but happily, Northstowe inserts right before Oakington in the alphabetical list, so I decided to add it, visiting both the old and new in the same day.
There are a bunch of other minor edge cases. Some villages have an outlying hamlet. Mostly I included these. There are some individual farms, which I generally didn t count.
Some stats
I visited 150 villages plus the Lords Bridge radio observatory. The project took 3 years and 3 months to complete.
There were 96 rides, totalling about 4900km. So my mean distance was around 51km. The median distance per ride was a little higher, at around 52 km, and the median duration (including stoppages) was about 2h40. The total duration, if you add them all up, including stoppages, was about 275h, giving a mean speed including photo stops, lunches and all, of 18kph.
The longest ride was 89.8km, collecting Scotland Farm, Shepreth, and Six Mile Bottom, so riding across the Cam valley. The shortest ride was 7.9km, collecting Cambridge (obviously); and I think that s the only one I did on my Brompton. The rest were all on my trusty Thorn Audax.
My fastest ride (ranking by distance divided by time spent in motion) was to collect Haddenham, where I covered 46.3km in 1h39, giving an average speed in motion of 28.0kph.
The most I collected in one day was 5 places: West Wickham, West Wratting, Westley Bottom, Westley Waterless, and Weston Colville. That was the day of the Wests. (There s only one East: East Hatley.)
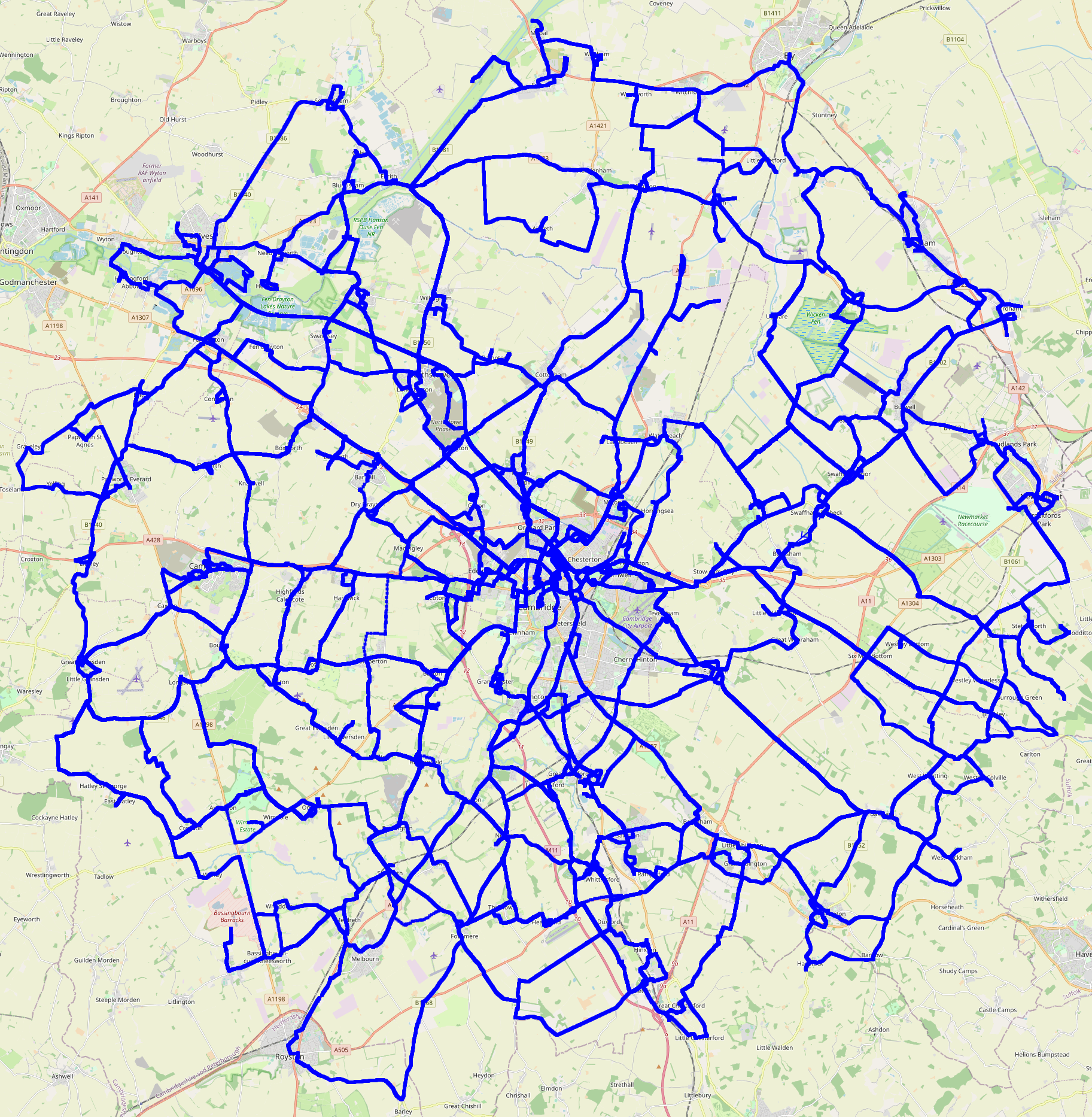
Map
Here is a pretty picture of all of my tracklogs:
 Edited 2023-08-25 01:32 BST to correct a slip.
Edited 2023-08-25 01:32 BST to correct a slip.chroot /target bash
apt-get install sysvinit-core elogind ntp dbus-x11
apt-get autoremove
exitapt-get install. If your disk arrangements are unusual, that may generate some error messages from update-initramfs.update-initramfs
The need to go back and have the installer reinstall grub is because if your storage is not very straightforward, the update-initramfs caused by apt-get install apparently doesn t have all the right context. I haven t investigated this at all; indeed, I don t even really know that the initramfs generated in step 3 above was broken, although the messages did suggest to me that important pieces or config might have been omitted. Instead, I simply chose to bet that it might be broken, but that the installer would know what to do. So I used the installer s install GRUB bootloader option, which does regenerate the initramfs. So, I don t know that step 6 is necessary.
In principle it would be better to do the switch from systemd to sysvinit earlier in the installation process, and under the control of the installer. But by default the installer goes straight from the early setup questions through to the set the time or reboot questions, without stopping. One could use the expert mode, or modify the command line, or something, but all of those things are, in practice, a lot more typing and/or interaction. And as far as I m aware the installer doesn t have an option for avoiding systemd .
The apt-get install line
sysvinit-core is the principal part of the sysvinit init system. Asking to install that causes the deinstallation of systemd s init and ancillary packages.
systemd refuses to allow itself to be deinstalled, if it is already running, so if you boot into the systemd system you can t then switch init system. This is why the switch is best done at install time. If you re too late, there are instructions for changing init system post-installation.
elogind is a forked version of some of systemd s user desktop session functionality. In practice modern desktop environments need this; without it, apt will want to remove things you probably want to keep. Even if you force it, you may find that your desktop environment can t adjust the audio volume, etc.
ntp is needed because nowadays the default network time client is systemd-timesyncd (which is a bad idea even on systems with systemd as init). We need to specify it because the package dependencies don t automatically give you any replacement for systemd-timesyncd.
dbus-x11 is a glue component. In theory it ought to be installed automatically. However, there have been problems with the dependencies that meant that (for example) asking for emacs would try to switch the init system. Specifying dbus-x11 explicitly is a workaround for that, which I nowadays adopt out of caution. Perhaps it is no longer needed.
(On existing systems, it may be necessary to manually install orphan-sysvinit-scripts, which exists as a suboptimal technical workaround for the sociopolitical problems of hostile package maintainers and Debian s governance failures. The recipe above seems to install this package automatically.)
usrmerge
This recipe results in a system which has merged-/usr via symlinks. This configuration is a bad one. Ideally usrmerge-via-symlinks would be avoided.
The un-merged system is declared not officially supported by Debian and key packages try very hard to force it on users. However, merged-/usr-via-symlinks is full of bugs (mostly affecting package management) which are far too hard to fix (a project by some folks to try to do so has given up).
I suspect un-merged systems will suffer from fewer bugs in practice. But I don t know how to persuade d-i to make one.
Installer images
I think there is room in the market for an unofficial installer image which installs without systemd and perhaps without usrmerge. I don t have the effort for making such a thing myself.
Conclusion
Installing Debian without systemd is fairly straightforward.
Operating Debian without systemd is a pleasure and every time one of my friends has some systemd-induced lossage I get to feel smug.rust-<name-of-crate> is probably in violation.
There are a number of more detailed problems with the wording.
Values
The policy has all the hallmarks of excessive influence from traditional trademark lawyers and not enough influence from the Free Software community.
I would like to remind the Free Software activists on the inside of this process that the lawyers are there to serve you and the community.
The values embodied in trademark law often conflict with the values of the Free Software community. The Rust Project should adopt a trademark policy which follows the community s values - even if that might weaken our ability to sue evildoers.
Next steps
The Foundation should take a step back and pause the process.
Then, the Foundation should restart the process from a much earlier stage, with much wider publicity. Each stage should be widely advertised to the whole community, with opportunities for feedback.
This should include publishing the results of the August 2022 survey. The Foundation should publish a sketch of the legal advice they have received, publicly say what the plausible options are and what their consequences might be (for the community, for downstreams, and for the Foundation s enforcement ability).
(Some of this will no doubt repeat the work that has been done in the informal trademark working group. That work wasn t widely enough advertised.)
Echoes of a dispute from 2006
Mozilla made a very similar mistake with Firefox in 2006.
The official policy stated that no-one was allowed to distribute Firefox with any patches, unless those patches had been pre-approved by Mozilla.
Debian is committed to Software Freedom. This must includes the freedom to modify the software as one sees fit, even if the original authors don t agree.
Now, overly-restrictive trademark policies are hardly new. Debian often takes the practical view that usually the upstream with such a policy doesn t really mean it.
But Mozilla decided they did mean it. They contacted Debian asking for Debian to get their patches approved.
Since that wasn t acceptable to Debian, they stopped using the word Firefox . For a decade, Debian s Firefox browser was called Iceweasel .
We don t want something similar happening to Rust .derive macro without having to mess with procedural macros?
Now you can!
derive-adhoc lets you write a #[derive] macro, using a template syntax which looks a lot like macro_rules!.
It s still 0.x - so unstable, and maybe with sharp edges. We want feedback!
And, the documentation is still very terse. It is doesn t omit anything, but, it is severely lacking in examples, motivation, and so on. It will suit readers who enjoy dense reference material.
( Read more... )secnet - VPN.hippotat - IP-over-HTTP (workaround for bad networks)userv ipif - user-created network interfacesHippotat is a system to allow you to use your normal VPN, ssh, and other applications, even in broken network environments that are only ever tested with web stuff . Packets are parcelled up into HTTP POST requests, resembling form submissions (or JavaScript XMLHttpRequest traffic), and the returned packets arrive via the HTTP response bodies.It doesn t rely on TLS tunnelling so can work even if the local network is trying to intercept TLS. I recently rewrote Hippotat in Rust.
userv ipif
userv ipif is one of the userv utilities.
It allows safe delegation of network routing to unprivileged users. The delegation is of a specific address range, so different ranges can be delegated to different users, and the authorised user cannot interfere with other traffic.
This is used in the default configuration of hippotat packages, so that an ordinary user can start up the hippotat client as needed.
On chiark userv-ipif is used to delegate networking to users, including administrators of allied VPN realms. So chiark actually runs at least 4 VPN-ish systems in production: secnet, hippotat, Mark Wooding s Tripe, and still a few links managed by the now-superseded udptunnel system.
userv
userv ipif is a userv service. That is, it is a facility which uses userv to bridge a privilege boundary.
userv is perhaps my most under-appreciated program. userv can be used to straightforwardly bridge (local) privilege boundaries on Unix systems.
So for example it can:
sudo can do this too but it has quite a few gotchas, and you have to be quite careful how you use it - and its security record isn t great either.hippotat client is a program you can run from the command line as a normal user, if the relevant network addresses have been delegated to you. On chiark, CGI programs run as the providing user - not using suexec (which I don t trust), but via userv.Next.