Dirk Eddelbuettel: #37: Introducing r2u with 2 x 19k CRAN binaries for Ubuntu 22.04 and 20.04
 One month ago I started work on a new side project which is now up and running, and deserving on an introductory blog post: r2u. It was announced in two earlier tweets (first, second) which contained the two (wicked) demos below also found at the documentation site.
So what is this about? It brings full and complete CRAN installability to Ubuntu LTS, both the focal release 20.04 and the recent jammy release 22.04. It is unique in resolving all R and CRAN packages with the system package manager. So whenever you install something it is guaranteed to run as its dependencies are resolved and co-installed as needed. Equally important, no shared library will be updated or removed by the system as the possible dependency of the R package is known and declared. No other package management system for R does that as only
One month ago I started work on a new side project which is now up and running, and deserving on an introductory blog post: r2u. It was announced in two earlier tweets (first, second) which contained the two (wicked) demos below also found at the documentation site.
So what is this about? It brings full and complete CRAN installability to Ubuntu LTS, both the focal release 20.04 and the recent jammy release 22.04. It is unique in resolving all R and CRAN packages with the system package manager. So whenever you install something it is guaranteed to run as its dependencies are resolved and co-installed as needed. Equally important, no shared library will be updated or removed by the system as the possible dependency of the R package is known and declared. No other package management system for R does that as only apt on Debian or Ubuntu can and this project integrates all CRAN packages (plus 200+ BioConductor packages). It will work with any Ubuntu installation on laptop, desktop, server, cloud, container, or in WSL2 (but is limited to Intel/AMD chips, sorry Raspberry Pi or M1 laptop). It covers all of CRAN (or nearly 19k packages), all the BioConductor packages depended-upon (currently over 200), and only excludes less than a handful of CRAN packages that cannot be built.
Usage
Setup instructions approaches described concisely in the repo README.md and documentation site. It consists of just five (or fewer) simple steps, and scripts are provided too for focal (20.04) and jammy (22.04).
Demos
Check out these two demos (also at the r2u site):
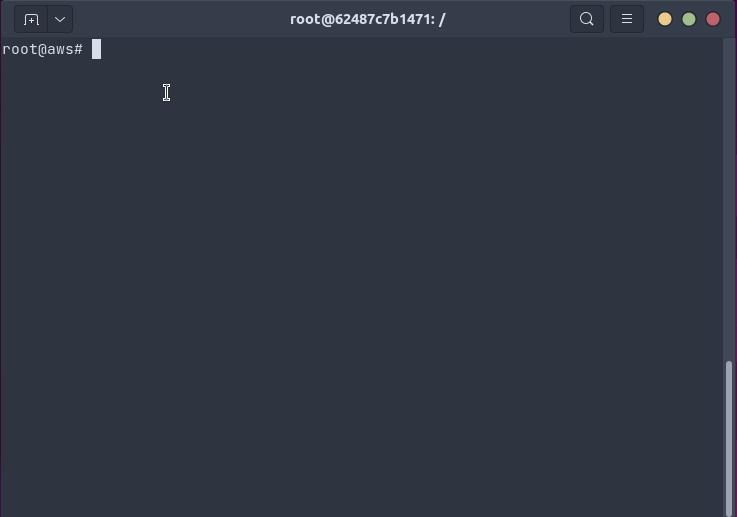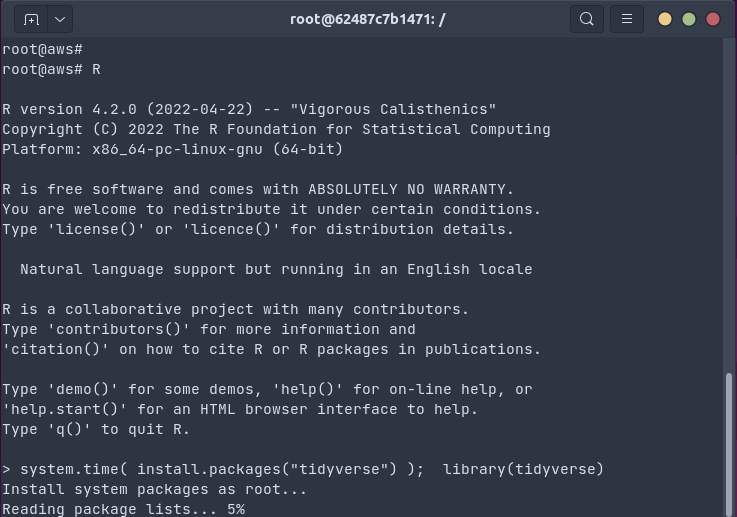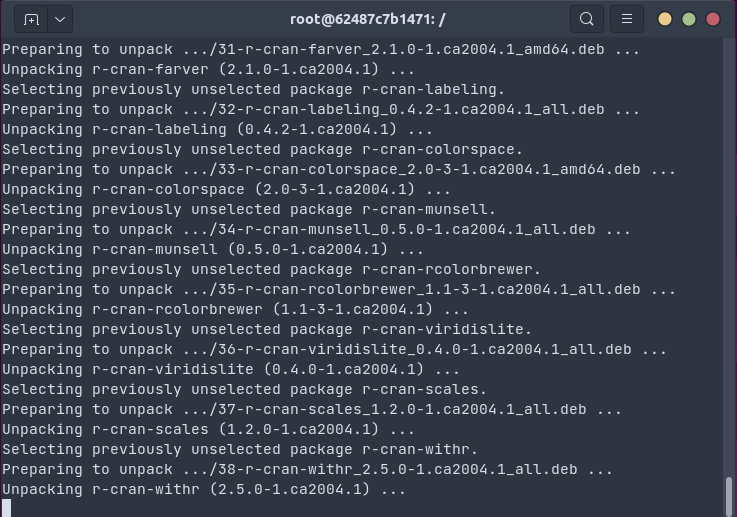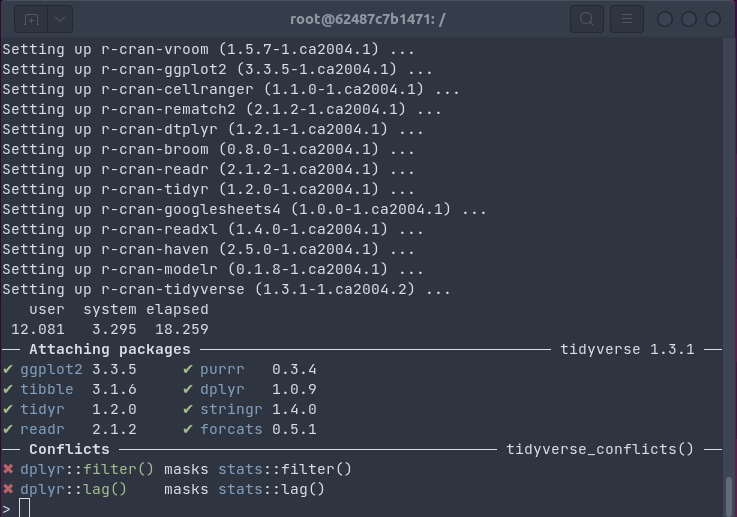
Installing the full tidyverse in one command and 18 seconds
Installing brms and its depends in one command and 13 seconds (and show gitpod.io)
Integration via bspm
The r2u setup can be used directly with apt (or dpkg or any other frontend to the package management system). Once installed apt update; apt upgrade will take care of new packages. For this to work, all CRAN packages (and all BioConductor packages depended upon) are mapped to names like r-cran-rcpp and r-bioc-s4vectors: an r prefix, the repo, and the package name, all lower-cased. That works but thanks to the wonderful bspm package by I aki car we can do much better. It connects R s own install.packages() and update.packages() to apt. So we can just say (as the demos above show) install.packages("tidyverse") or install.packages("brms") and binaries are installed via apt which is fantastic and it connects R to the system package manager. The setup is really only two lines and described at the r2u site as part of the setup.
History and Motivation
Turning CRAN packages into .deb binaries is not a new idea. Albrecht Gebhardt was the first to realize this about twenty years ago (!!) and implemented it with a single Perl script. Next, Albrecht, Stefan Moeller, David Vernazobres and I built on top of this which is described in this useR! 2007 paper. A most excellent generalization and rewrite was provided by Charles Blundell in an superb Google Summer of Code contribution in 2008 which I mentored. Charles and I described it in this talk at useR! 2009. I ran that setup for a while afterwards, but it died via an internal database corruption in 2010 right when I tried to demo it at CRAN headquarters in Vienna. This peaked at, if memory serves, about 5k packages: all of CRAN at the time. Don Armstrong took it one step further in a full reimplemenation which, if I recall correctly, coverd all of CRAN and BioConductor for what may have been 8k or 9k packages. Don had a stronger system (with full RAID-5) but it also died in a crash and was never rebuilt even though he and I could have relied on Debian resources (as all these approaches focused on Debian). During that time, Michael Rutter created a variant that cleverly used an Ubuntu-only setup utilizing Launchpad. This repo is still going strong, used and relied-upon by many, and about 5k packages (per distribution) strong. At one point, a group consisting of Don, Michael, G bor Cs rdi and myself (as lead/PI) had financial support from the RConsortium ISC for a more general re-implementation , but that support was withdrawn when we did not have time to deliver.
We should also note other long-standing approaches. Detlef Steuer has been using the openSUSE Build Service to provide nearly all of CRAN for openSUSE for many years. I aki car built a similar system for Fedora described in this blog post. I aki and I also have a arXiv paper describing all this.
Details
Please see the the r2u site for all details on using r2u.
Acknowledgements
The help of everybody who has worked on this is greatly appreciated. So a huge Thank you! to Albrecht, David, Stefan, Charles, Don, Michael, Detlef, G bor, I aki and whoever I may have omitted. Similarly, thanks to everybody working on R, CRAN, Debian, or Ubuntu it all makes for a superb system. And another big Thank you! goes to my GitHub sponsors whose continued support is greatly appreciated.
Installing the full tidyverse in one command and 18 seconds
Installing brms and its depends in one command and 13 seconds (and show gitpod.io)
Integration via bspm
The r2u setup can be used directly with apt (or dpkg or any other frontend to the package management system). Once installed apt update; apt upgrade will take care of new packages. For this to work, all CRAN packages (and all BioConductor packages depended upon) are mapped to names like r-cran-rcpp and r-bioc-s4vectors: an r prefix, the repo, and the package name, all lower-cased. That works but thanks to the wonderful bspm package by I aki car we can do much better. It connects R s own install.packages() and update.packages() to apt. So we can just say (as the demos above show) install.packages("tidyverse") or install.packages("brms") and binaries are installed via apt which is fantastic and it connects R to the system package manager. The setup is really only two lines and described at the r2u site as part of the setup.
History and Motivation
Turning CRAN packages into .deb binaries is not a new idea. Albrecht Gebhardt was the first to realize this about twenty years ago (!!) and implemented it with a single Perl script. Next, Albrecht, Stefan Moeller, David Vernazobres and I built on top of this which is described in this useR! 2007 paper. A most excellent generalization and rewrite was provided by Charles Blundell in an superb Google Summer of Code contribution in 2008 which I mentored. Charles and I described it in this talk at useR! 2009. I ran that setup for a while afterwards, but it died via an internal database corruption in 2010 right when I tried to demo it at CRAN headquarters in Vienna. This peaked at, if memory serves, about 5k packages: all of CRAN at the time. Don Armstrong took it one step further in a full reimplemenation which, if I recall correctly, coverd all of CRAN and BioConductor for what may have been 8k or 9k packages. Don had a stronger system (with full RAID-5) but it also died in a crash and was never rebuilt even though he and I could have relied on Debian resources (as all these approaches focused on Debian). During that time, Michael Rutter created a variant that cleverly used an Ubuntu-only setup utilizing Launchpad. This repo is still going strong, used and relied-upon by many, and about 5k packages (per distribution) strong. At one point, a group consisting of Don, Michael, G bor Cs rdi and myself (as lead/PI) had financial support from the RConsortium ISC for a more general re-implementation , but that support was withdrawn when we did not have time to deliver.
We should also note other long-standing approaches. Detlef Steuer has been using the openSUSE Build Service to provide nearly all of CRAN for openSUSE for many years. I aki car built a similar system for Fedora described in this blog post. I aki and I also have a arXiv paper describing all this.
Details
Please see the the r2u site for all details on using r2u.
Acknowledgements
The help of everybody who has worked on this is greatly appreciated. So a huge Thank you! to Albrecht, David, Stefan, Charles, Don, Michael, Detlef, G bor, I aki and whoever I may have omitted. Similarly, thanks to everybody working on R, CRAN, Debian, or Ubuntu it all makes for a superb system. And another big Thank you! goes to my GitHub sponsors whose continued support is greatly appreciated.
Integration via bspm
The r2u setup can be used directly with apt (or dpkg or any other frontend to the package management system). Once installed apt update; apt upgrade will take care of new packages. For this to work, all CRAN packages (and all BioConductor packages depended upon) are mapped to names like r-cran-rcpp and r-bioc-s4vectors: an r prefix, the repo, and the package name, all lower-cased. That works but thanks to the wonderful bspm package by I aki car we can do much better. It connects R s own install.packages() and update.packages() to apt. So we can just say (as the demos above show) install.packages("tidyverse") or install.packages("brms") and binaries are installed via apt which is fantastic and it connects R to the system package manager. The setup is really only two lines and described at the r2u site as part of the setup.
History and Motivation
Turning CRAN packages into .deb binaries is not a new idea. Albrecht Gebhardt was the first to realize this about twenty years ago (!!) and implemented it with a single Perl script. Next, Albrecht, Stefan Moeller, David Vernazobres and I built on top of this which is described in this useR! 2007 paper. A most excellent generalization and rewrite was provided by Charles Blundell in an superb Google Summer of Code contribution in 2008 which I mentored. Charles and I described it in this talk at useR! 2009. I ran that setup for a while afterwards, but it died via an internal database corruption in 2010 right when I tried to demo it at CRAN headquarters in Vienna. This peaked at, if memory serves, about 5k packages: all of CRAN at the time. Don Armstrong took it one step further in a full reimplemenation which, if I recall correctly, coverd all of CRAN and BioConductor for what may have been 8k or 9k packages. Don had a stronger system (with full RAID-5) but it also died in a crash and was never rebuilt even though he and I could have relied on Debian resources (as all these approaches focused on Debian). During that time, Michael Rutter created a variant that cleverly used an Ubuntu-only setup utilizing Launchpad. This repo is still going strong, used and relied-upon by many, and about 5k packages (per distribution) strong. At one point, a group consisting of Don, Michael, G bor Cs rdi and myself (as lead/PI) had financial support from the RConsortium ISC for a more general re-implementation , but that support was withdrawn when we did not have time to deliver.
We should also note other long-standing approaches. Detlef Steuer has been using the openSUSE Build Service to provide nearly all of CRAN for openSUSE for many years. I aki car built a similar system for Fedora described in this blog post. I aki and I also have a arXiv paper describing all this.
Details
Please see the the r2u site for all details on using r2u.
Acknowledgements
The help of everybody who has worked on this is greatly appreciated. So a huge Thank you! to Albrecht, David, Stefan, Charles, Don, Michael, Detlef, G bor, I aki and whoever I may have omitted. Similarly, thanks to everybody working on R, CRAN, Debian, or Ubuntu it all makes for a superb system. And another big Thank you! goes to my GitHub sponsors whose continued support is greatly appreciated.
Details
Please see the the r2u site for all details on using r2u.
Acknowledgements
The help of everybody who has worked on this is greatly appreciated. So a huge Thank you! to Albrecht, David, Stefan, Charles, Don, Michael, Detlef, G bor, I aki and whoever I may have omitted. Similarly, thanks to everybody working on R, CRAN, Debian, or Ubuntu it all makes for a superb system. And another big Thank you! goes to my GitHub sponsors whose continued support is greatly appreciated.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.

 Like many laptop users, I often plug my laptop into different monitor
setups (multiple monitors at my desk, projector when presenting, etc.)
Running xrandr commands or clicking through interfaces gets tedious,
and writing scripts isn't much better.
Recently, I ran
across
Like many laptop users, I often plug my laptop into different monitor
setups (multiple monitors at my desk, projector when presenting, etc.)
Running xrandr commands or clicking through interfaces gets tedious,
and writing scripts isn't much better.
Recently, I ran
across  For the non-Debian people among my readers: The following post presents bits of the decision-taking process in the Debian project. You might find it interesting, or terribly dull and boring :-) Proceed at your own risk.
My reason for posting this entry is to get more people to read the accompanying options for my proposed General Resolution (GR), and have as full a ballot as possible.
Almost three weeks ago, I sent
For the non-Debian people among my readers: The following post presents bits of the decision-taking process in the Debian project. You might find it interesting, or terribly dull and boring :-) Proceed at your own risk.
My reason for posting this entry is to get more people to read the accompanying options for my proposed General Resolution (GR), and have as full a ballot as possible.
Almost three weeks ago, I sent  I woke up this morning and realized that for the first time since
I woke up this morning and realized that for the first time since
 Long long time ago I wanted to have
Long long time ago I wanted to have  I have already updated the packaging for the latest version 0.8.7, which will be included in Debian/sid rather soon. Thanks again especially Mattia for his great work.
I have already updated the packaging for the latest version 0.8.7, which will be included in Debian/sid rather soon. Thanks again especially Mattia for his great work.







 Unfortunately I was not able to attend debconf this year but thanks to the
awesome video team the all the talks
Unfortunately I was not able to attend debconf this year but thanks to the
awesome video team the all the talks 


 The process has been ongoing for
The process has been ongoing for 