Every year or so, I revisit the current best practices for Python packaging.
I.e. the way you re supposed to distribute your Python packages. The main
source is
packaging.python.org where the official packaging guidelines
are. It is worth noting that the way you re supposed to package your Python
applications is
not defined by Python or its maintainers, but rather
delegated to a separate entity, the
Python Packaging Authority (PyPA).
PyPA
PyPA does an excellent job providing us with information, best practices and
tutorials regarding Python packaging. However, there s
one thing that
irritates me every single time I revisit the page and that is the misleading
recommendation of their
own tool
pipenv.
Quoting from the
tool recommendations section of the packaging
guidelines:
Use Pipenv to manage library dependencies when developing Python
applications. See Managing Application Dependencies for more details on
using pipenv.
PyPA recommends
pipenv as the
standard tool for dependency
management, at least
since 2018. A bold statement, given that
pipenv only started in 2017, so the Python community cannot have had not
enough time to standardize on the workflow around that tool. There have been
no releases of
pipenv between 2018-11 and 2020-04, that s 1.5 years for the
standard tool. In the past,
pipenv also hasn t been shy in pushing
breaking changes in a fast-paced manner.
PyPA still advertises
pipenv all over the place and only mentions
poetry
a couple of times, although
poetry seems to be the more mature product. I
understand that
pipenv lives under the umbrella of PyPA, but I still expect
objectiveness when it comes to tool recommendation. Instead of making such
claims, they should provide a list of competing tools and provide a fair
feature comparison.
Distributions
You would expect exactly one distribution for Python packages, but here in
Python land, we have several ones. The most popular ones being
PyPI the
official one and
Anaconda. Anaconda is more geared towards
data-scientists. The main selling point for Anaconda back then was that it
provided pre-compiled binaries. This was especially useful for data-science
related packages which depend on libatlas, -lapack, -openblas, etc. and need
to be compiled for the target system. This problem has mostly been solved with
the wide adoption of
wheels, but you still encounter some source-only
uploads to PyPI that require you to build stuff locally on
pip install.
Of course there s also the Python packages distributed by the Operating
System, Debian in my case. While I was a firm believer in
only using those
packages provided by the OS in the very past, I moved to the opposite end of
the spectrum throughout the years, and am
only using the minimal packages
provided by Debian to bootstrap my virtual environments (i.e.
pip,
setuptools and
wheel). The main reason is outdated or missing libraries,
which is expected Debian cannot hope to keep up with all the upstream
changes in the ecosystem, and that is by design and fine. However, with the
recent upgrade of
manylinux, even the
pip provided by Debian/unstable
was too outdated, so you basically had to
pip install --upgrade pip for a
while otherwise you d end up compiling every package you d try to install via
pip.
So I m sticking to the official PyPI distribution wherever possible. However,
compared to the Debian distribution it feels immature. In my opinion, there
should be compiled wheels for all packages available that need it, built and
provided by PyPI. Currently, the wheels provided are the ones uploaded by the
upstream maintainers. This is not enough, as they usually build wheels only
for one platform. Sometimes they don t upload wheels in the first place,
relying on the users to compile during install.
Then you have
manylinux, an excellent idea to create some common ground
for a portable Linux build distribution. However, sometimes when a new version
of manylinux is released some upstream maintainers immediately start
supporting
only that version, breaking a lot of systems.
A setup similar to Debian s where the authors only do a source-upload and the
wheels are compiled on PyPI infrastructure for all available platforms, is
probably the way to go.
setup.py, setup.cfg, requirements.txt. Pipfile, pyproject.toml oh my!
This is the part I m revisiting the documentation every year, to see what s
the current way to go.
The main point of packaging your Python application is to define the package s
meta data and (build-) dependencies.
setup.py + requirements.txt
For the longest time, the
setup.py and
requirements.txt were (and, spoiler
alert: still is) the backbone of your packaging efforts. In
setup.py you
define the meta data of your package, including its dependencies.
If your project is a deployable application (vs. a library) you ll very often
provide an additional
requirements.txt with
pinned dependencies. Usually
the list of requirements is the same as defined in
setup.py but with pinned
versions. The reason why you avoid version pinning in
setup.py is that it
would interfere with other pinned dependencies from other dependencies you try
to install.
setup.cfg
setup.cfg is a configuration file that is used by many standard tools in the
Python ecosystem. Its format is ini-style and each tools configuration lives
in its own stanza. Since 2016
setuptools supports configuring
setup() using
setup.cfg files. This was exciting news back then, however,
it does not completely replace the
setup.py file. While you can move most of
the
setup.py configuration into
setup.cfg, you ll still have to provide
that file with an empty
setup() in order to allow for editable
pip
installs. In my opinion, that makes this feature useless and I rather stick to
setup.py with a properly populated
setup() until that file can be
completely replaced with something else.
Pipfile + Pipflie.lock
Pipfile and Pipfile.lock are supposed to replace
requirements.txt some day. So far they are not supported by
pip or
mentioned in any
PEP. I think only
pipenv supports them, so I d ignore
them for now.
pyproject.toml
PEP 518 introduces the
pyproject.toml file as a way to specify
build requirements for your project.
PEP 621 defines how to store
project meta data in it.
pip and
setuptools support
pyproject.toml to some extent, but not to a
point where it completely replaces
setup.py yet. Many of Python s standard
tools allow already for configuration in
pyproject.toml so it seems this
file will slowly replace the
setup.cfg and probably
setup.py and
requirements.txt as well. But we re not there yet.
poetry has an interesting approach: it will allow you to write everything
into
pyproject.toml and
generate a
setup.py for you at build-time, so it
can be uploaded to PyPI.
Ironically, Python settled for the TOML file format here, although there is
currently no support for reading TOML files in Python s standard library.
Summary
While some alternatives exist, in 2021 I still stick to
setup.py and
requirements.txt to define the meta data and dependencies of my projects.
Regarding the tooling,
pip and
twine are sufficient and do their job just
fine. Alternatives like
pipenv and
poetry exist. The scope of
poetry
seems to be better aligned with my expectations, and it seems the more mature
project compared to
pipenv but in any case I ll ignore both of them until I
revisit this issue in 2022.
Closing Thoughts
While the packaging in Python has improved a lot in the last years, I m still
somewhat put off how such a core aspect of a programming language is treated
within Python. With some jealousy, I look over to the folks at Rust and how
they seemed to get this aspect right from the start.
What would in my opinion improve the situation?
- Source only uploads and building of weels for all platforms on PyPI
infrastructure this way we could have wheels everywhere and remove the
need to compile anything in
pip install
- Standard tooling:
pip has been and still is the tool of choice for
packaging in Python. For some time now, you also need twine in order to
upload your packages. setup.py upload still exists, but hasn t worked for
months on my machines. It would be great to have something that improves the
virtualenv handling and dependency management. We do have some tools with
overlapping use-cases, like poetry and pipenv. pipenv is heavily
advertised and an actual PyPA project, but it feels immature in terms of
scope, release history (and emojis!) compared to poetry. poetry is
gaining a lot of traction, but it is apparently not receiving much love from
PyPA, which brings me to:
- Unbiased tool recommendations. I don t understand why PyPA is trying so hard
to make us believe
pipenv would be the standard tool for Python packaging.
Instead of making such claims, please provide a list of competitors and
provide a fair feature comparison. PyPA is providing great packaging
tutorials and is a valuable source of information around this topic. But
when it comes to the tool recommendations, I do challenge PyPA s
objectiveness.


 It comes with a light- and dark theme that switches automatically based on the
browser setting, as well as fitting light- and dark syntax highlighting themes
for code blocks.
Improved
It comes with a light- and dark theme that switches automatically based on the
browser setting, as well as fitting light- and dark syntax highlighting themes
for code blocks.
Improved  I know, I m for sure not the first one to discover this kind of thing, but it
was a fun afternoon project anyways!
I know, I m for sure not the first one to discover this kind of thing, but it
was a fun afternoon project anyways!
 I know, I m for sure not the first one to discover this kind of thing, but it
was a fun afternoon project anyways!
I know, I m for sure not the first one to discover this kind of thing, but it
was a fun afternoon project anyways!

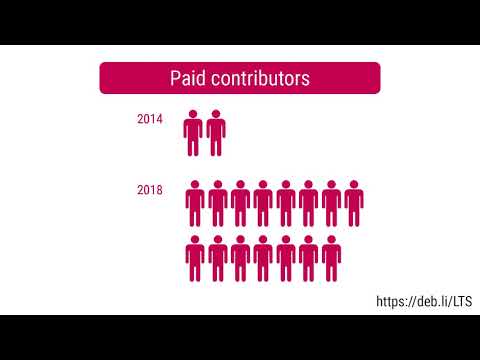
 Here is my monthly update covering what I have been doing in the free software world during February 2020 (
Here is my monthly update covering what I have been doing in the free software world during February 2020 (