The Ruby team is working now on transitioning to ruby 3.0. Even though most
packages will work just fine, there is substantial amount of packages that
require some work to adapt. We have been doing test rebuilds for a while during
transitions, but usually triaged the problems manually.
This time I decided to try
collab-qa-tools, a set of
scripts Lucas Nussbaum uses when he does archive-wide rebuilds. I'm really glad
that I did, because those tols save a lot of time when processing a large
number of build failures. In this post, I will go through how to triage a set
of build logs using collab-qa-tools.
I have
some
some
improvements
to the code. Given my last merge request is very new and was not merged yet,
a few of the things I mention here may apply only to
my own ruby3.0 branch.
collab-qa-tools also contains a few tools do perform the builds in the
cloud, but since we already had the builds done, I will not be mentioning that
part and will write exclusively about the triaging tools.
Installing collab-qa-tools
The first step is to clone the git repository. Make sure you have the
dependencies from
debian/control installed (a few Ruby libraries).
One of the patches I sent, and was already accepted, is the ability to run it
without the need to install:
source /path/to/collab-qa-tools/activate.sh
This will add the tools to your $PATH.
Preparation
The first think you need to do is getting all your build logs in a directory.
The tools assume
.log file extension, and they can be named
$ PACKAGE _*.log or just
$ PACKAGE .log.
Creating a TODO file
cqa-scanlogs grep -v OK > todo
todo will contain one line for each log with a summary of the failure, if
it's able to find one. collab-qa-tools has a large set of regular expressions
for finding errors in the build logs
It's a good idea to split the TODO file in multiple ones. This can easily be
done with
split(1), and can be used to delimit triaging sessions, and/or to
split the triaging between multiple people. For example this will create
todo into
todo00,
todo01, ..., each containing 30 lines:
split --lines=30 --numeric-suffixes todo todo
Triaging
You can now do the triaging. Let's say we split the TODO files, and will start
with
todo01.
The first step is calling
cqa-fetchbugs (it does what it says on the tin):
cqa-fetchbugs --TODO=todo01
Then,
cqa-annotate will guide you through the logs and allow you to report
bugs:
cqa-annotate --TODO=todo01
I wrote myself a
process.sh wrapper script for
cqa-fetchbugs and
cqa-annotate that looks like this:
#!/bin/sh
set -eu
for todo in $@; do
# force downloading bugs
awk ' print(".bugs." $1) ' "$ todo " xargs rm -f
cqa-fetchbugs --TODO="$ todo "
cqa-annotate \
--template=template.txt.jinja2 \
--TODO="$ todo "
done
The
--template option is a recent contribution of mine. This is a template
for the bug reports you will be sending. It uses
Liquid templates,
which is very similar to Jinja2 for Python. You will notice that I am even
pretending it
is Jinja2 to trick vim into doing syntax highlighting
for me. The template I'm using looks like this:
From: fullname < email >
To: submit@bugs.debian.org
Subject: package : FTBFS with ruby3.0: summary
Source: package
Version: version split:'+rebuild' first
Severity: serious
Justification: FTBFS
Tags: bookworm sid ftbfs
User: debian-ruby@lists.debian.org
Usertags: ruby3.0
Hi,
We are about to enable building against ruby3.0 on unstable. During a test
rebuild, package was found to fail to build in that situation.
To reproduce this locally, you need to install ruby-all-dev from experimental
on an unstable system or build chroot.
Relevant part (hopefully):
% for line in extract % > line
% endfor %
The full build log is available at
https://people.debian.org/~kanashiro/ruby3.0/round2/builds/3/ package / filename replace:".log",".build.txt"
The cqa-annotate loop
cqa-annotate will parse each log file, display an extract of what it found as
possibly being the relevant part, and wait for your input:
######## ruby-cocaine_0.5.8-1.1+rebuild1633376733_amd64.log ########
--------- Error:
Failure/Error: undef_method :exitstatus
FrozenError:
can't modify frozen object: pid 2351759 exit 0
# ./spec/support/unsetting_exitstatus.rb:4:in undef_method'
# ./spec/support/unsetting_exitstatus.rb:4:in singleton class'
# ./spec/support/unsetting_exitstatus.rb:3:in assuming_no_processes_have_been_run'
# ./spec/cocaine/errors_spec.rb:55:in block (2 levels) in <top (required)>'
Deprecation Warnings:
Using should from rspec-expectations' old :should syntax without explicitly enabling the syntax is deprecated. Use the new :expect syntax or explicitly enable :should with config.expect_with(:rspec) c c.syntax = :should instead. Called from /<<PKGBUILDDIR>>/spec/cocaine/command_line/runners/backticks_runner_spec.rb:19:in block (2 levels) in <top (required)>'.
If you need more of the backtrace for any of these deprecations to
identify where to make the necessary changes, you can configure
config.raise_errors_for_deprecations! , and it will turn the
deprecation warnings into errors, giving you the full backtrace.
1 deprecation warning total
Finished in 6.87 seconds (files took 2.68 seconds to load)
67 examples, 1 failure
Failed examples:
rspec ./spec/cocaine/errors_spec.rb:54 # When an error happens does not blow up if running the command errored before execution
/usr/bin/ruby3.0 -I/usr/share/rubygems-integration/all/gems/rspec-support-3.9.3/lib:/usr/share/rubygems-integration/all/gems/rspec-core-3.9.2/lib /usr/share/rubygems-integration/all/gems/rspec-core-3.9.2/exe/rspec --pattern ./spec/\*\*/\*_spec.rb --format documentation failed
ERROR: Test "ruby3.0" failed:
----------------
ERROR: Test "ruby3.0" failed: Failure/Error: undef_method :exitstatus
----------------
package: ruby-cocaine
lines: 30
------------------------------------------------------------------------
s: skip
i: ignore this package permanently
r: report new bug
f: view full log
------------------------------------------------------------------------
Action [s i r f]:
You can then choose one of the options:
-
s - skip this package and do nothing. You can run cqa-annotate again
later and come back to it.
-
i - ignore this package completely. New runs of cqa-annotate won't ask
about it again.
This is useful if the package only fails in your rebuilds due to another
package, and would just work when that other package gets fixes. In the Ruby
transition this happens when A depends on B, while B builds a C extension and
failed to build against the new Ruby. So once B is fixed, A should
just work (in principle). But even if A would even have problems of its own,
we can't really know before B is fixed so we can retry A.
-
r - report a bug. cqa-annotate will expand the template with the data
from the current log, and feed it to mutt. This is currently a limitation:
you have to use mutt to report bugs.
After you report the bug, cqa-annotate will ask if it should edit the TODO
file. In my opinion it's best to not do this, and annotate the package with a
bug number when you have one (see below).
f - view the full log. This is useful when the extract displayed doesn't
have enough info, or you want to inspect something that happened earlier (or
later) during the build.
When there are existing bugs in the package,
cqa-annotate will list them
among the options. If you choose a bug number, the TODO file will be annotated
with that bug number and new runs of
cqa-annotate will not ask about that
package anymore. For example after I reported a bug for
ruby-cocaine for the
issue listed above, I aborted with a
ctrl-c, and when I run my
process.sh
script again I then get this prompt:
----------------
ERROR: Test "ruby3.0" failed: Failure/Error: undef_method :exitstatus
----------------
package: ruby-cocaine
lines: 30
------------------------------------------------------------------------
s: skip
i: ignore this package permanently
1: 996206 serious ruby-cocaine: FTBFS with ruby3.0: ERROR: Test "ruby3.0" failed: Failure/Error: undef_method :exitstatus
r: report new bug
f: view full log
------------------------------------------------------------------------
Action [s i 1 r f]:
Chosing
1 will annotate the TODO file with the bug number, and I'm done with
this package. Only a few other hundreds to go.
 Em 2023 o tradicional
Em 2023 o tradicional 


 This is the report for the
This is the report for the 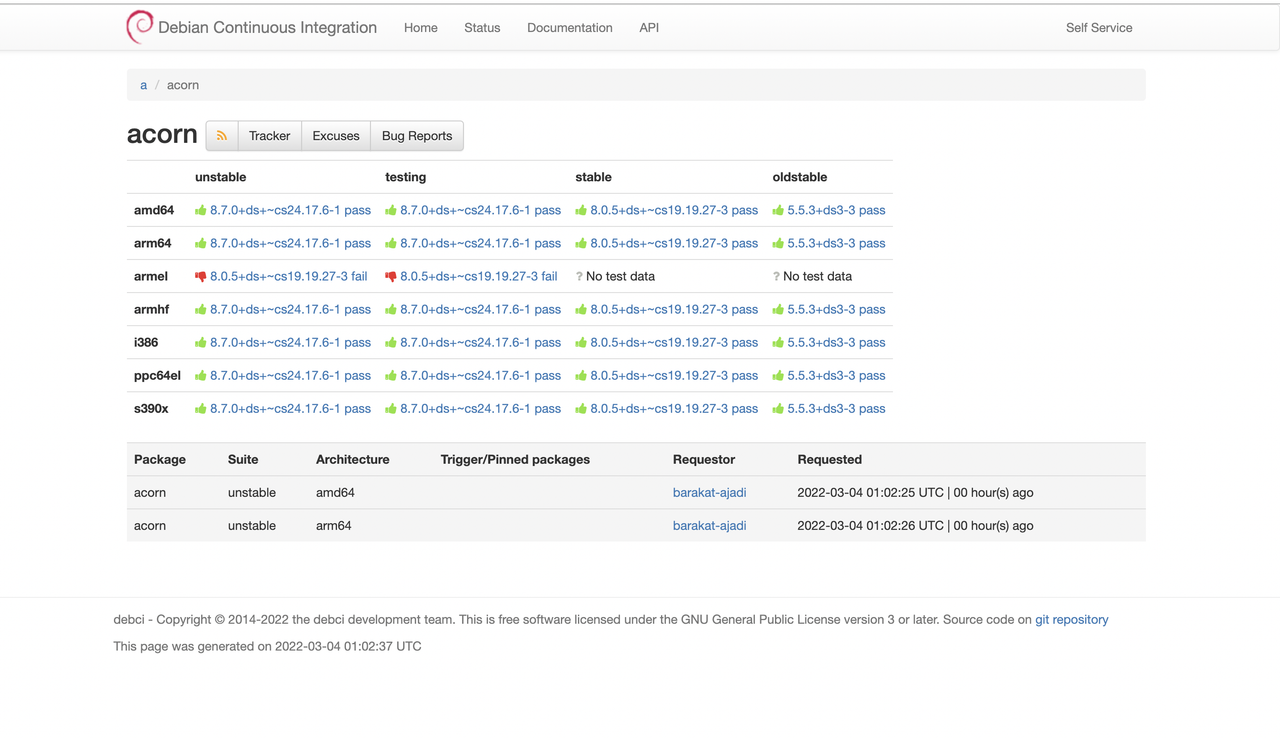
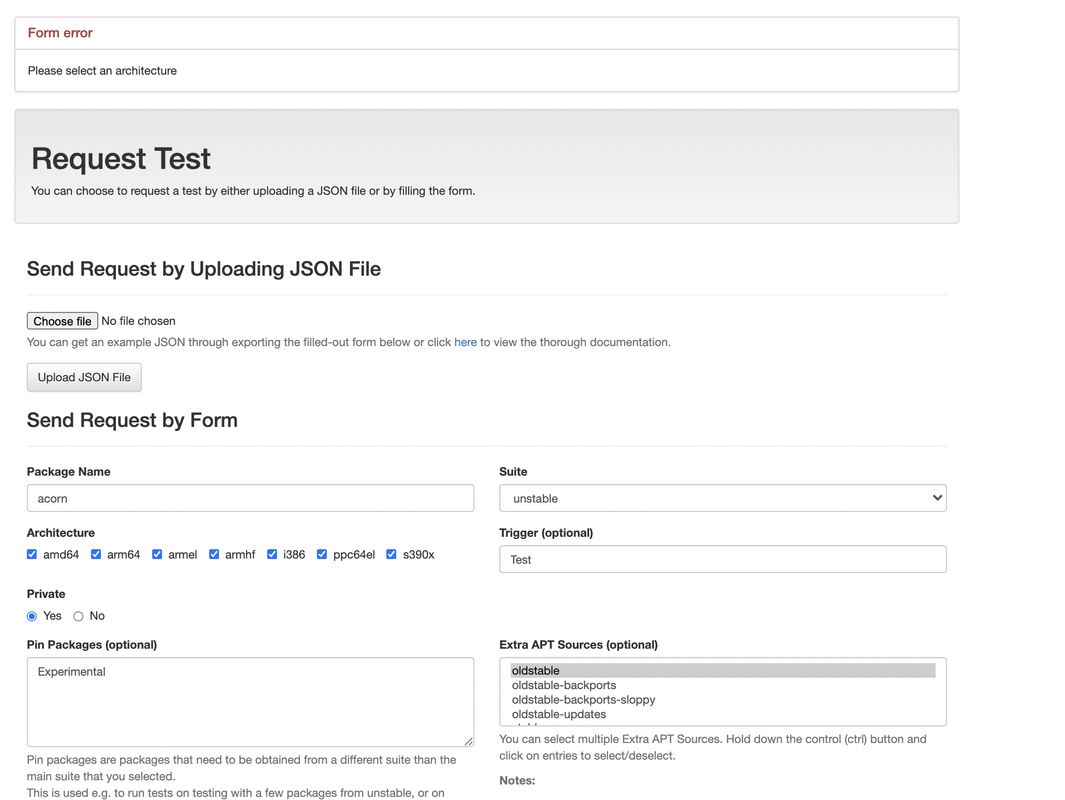 N/B: The form checks all architecture on the load of the page
N/B: The form checks all architecture on the load of the page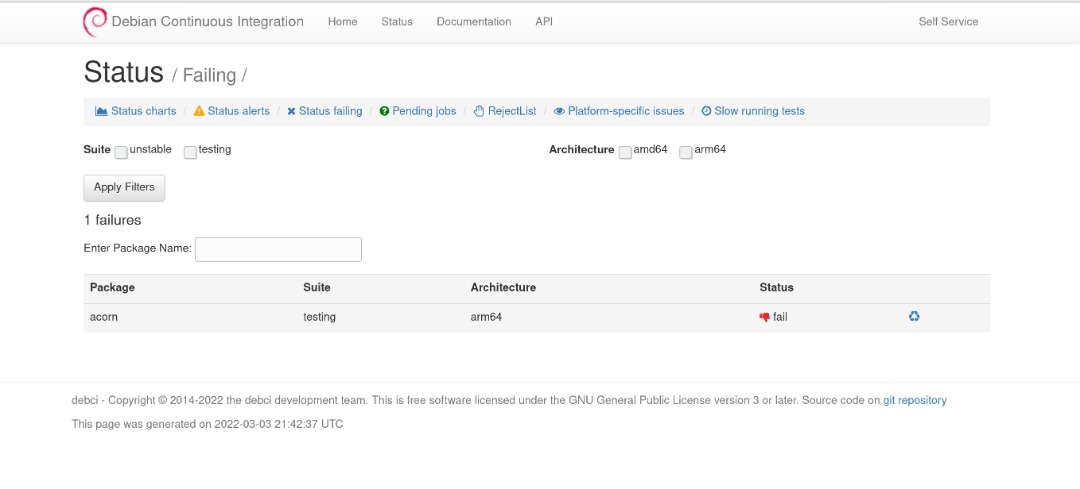 merge request:
merge request: Continuing with details of the task I left on
Continuing with details of the task I left on
 However, the growth rate seems to be decreasing. Maybe the low hanging fruit
have all been picked, or maybe we just need to help more people jump in the
automated testing bandwagon.
With that said, we would like to encourage and help more maintainers to add
autopkgtest to their packages. To that effect, I just created the
However, the growth rate seems to be decreasing. Maybe the low hanging fruit
have all been picked, or maybe we just need to help more people jump in the
automated testing bandwagon.
With that said, we would like to encourage and help more maintainers to add
autopkgtest to their packages. To that effect, I just created the
 I will be listing up my work done in the respective tasks.
I will be listing up my work done in the respective tasks.
 To start writing about updates regarding my GSoC project, the first obvious thing I need to do is to explain what my project really is. So let s get started.
To start writing about updates regarding my GSoC project, the first obvious thing I need to do is to explain what my project really is. So let s get started.
 I knew about GSoC since my first year of college but had this misconception that only great coders get selected for GSoC which did not let me apply to the program until my 3rd year of engineering. I applied this year not because I thought I have turned into one but because I actually wanted to give a fair try to this before the time I become ineligible to participate.
I knew about GSoC since my first year of college but had this misconception that only great coders get selected for GSoC which did not let me apply to the program until my 3rd year of engineering. I applied this year not because I thought I have turned into one but because I actually wanted to give a fair try to this before the time I become ineligible to participate.
 In May, I got selected as a
In May, I got selected as a 

 Following Antonio Terceiro s
Following Antonio Terceiro s  OK, one step back. Why are we doing this? Because our hardworking
friends of the DebConf20 video team recommended so. In order to
minimize connecitvity issues from the variety of speakers throughout
the world, we were requested to pre-record the exposition part of
our talks, send them to the video team (deadline: today
2020-08-16, in case you still owe yours!), and make sure to be present
at the end of the talk for the Q&A session. Of course, for a 45 minute
talk, I prepared a 30 minute presentation, saving time for said Q&A
session.
Anyway, I used the excellent
OK, one step back. Why are we doing this? Because our hardworking
friends of the DebConf20 video team recommended so. In order to
minimize connecitvity issues from the variety of speakers throughout
the world, we were requested to pre-record the exposition part of
our talks, send them to the video team (deadline: today
2020-08-16, in case you still owe yours!), and make sure to be present
at the end of the talk for the Q&A session. Of course, for a 45 minute
talk, I prepared a 30 minute presentation, saving time for said Q&A
session.
Anyway, I used the excellent