Daniel Stender: Theano in Debian: maintenance, BLAS and CUDA
I'm glad to announce that we have the current release of Theano (0.8.2) in Debian unstable now, it's on its way into the testing branch and the Debian derivatives, heading for Debian 9.
The Debian package is maintained in behalf of the Debian Science Team.
We have a binary package with the modules in the Python 2.7 import path (python-theano), if you want or need to stick to that branch a little longer (as a matter of fact, in the current popcon stats it's the most installed package), and a package running on the default Python 3 version (python3-theano).
The comprehensive documentation is available for offline usage in another binary package (theano-doc).
Although Theano builds its extensions on run time and therefore all binary packages contain the same code, the source package generates arch specific packages1 for the reason that the exhaustive test suite could run over all the architectures to detect if there are problems somewhere (#824116).
what's this?
In a nutshell, Theano is a computer algebra system (CAS) and expression compiler, which is implemented in Python as a library.
It is named after a Classical Greek female mathematician and it's developed at the LISA lab (located at MILA, the Montreal Institute for Learning Algorithms) at the Universit de Montr al.
Theano tightly integrates multi-dimensional arrays (N-dimensional, ND-array) from NumPy (
If the used Python version changed like in this example you might to want to purge obsolete cache.
For working with the cache resp. the compiledirs, the helper
The implementations are performing differently on different hardware, so you might want to take the time to compare which one does it best on your processor (the other packages are libatlas-base-dev and libopenblas-dev), and choose that to optimize your system.
If you want to squeeze out all which is in there for carrying out Theano's computations on the CPU, another option is to compile an optimized version of a BLAS library especially for your processor.
I'm going to write another blog posting on this issue.
The binary packages of Theano ship the script
hardware check
For running Theano on CUDA you need an NVIDIA graphics card which is capable of doing that.
You can recheck if your device is supported by CUDA here.
When the hardware isn't too old (CUDA support started with GeForce 8 and Quadro X series) or too strange I think it isn't working only in exceptional cases.
You can check your model and if the device is present in the system on the bare hardware level by doing this:
If a line like this doesn't get returned, your device most probably is broken, or not properly connected (ouch).
If
After doing that, perform
DKMS will then build the NVIDIA module for the kernel and does some other things on the system.
When the installation has finished, it's generally advised to reboot the system completely.
troubleshooting
If you have problems with the CUDA device, it's advised to verify if the following things concerning the NVIDIA driver resp. kernel module are in order:
blacklist nouveau
Check if the default Nouveau kernel module driver (which blocks the NVIDIA module) for some reason still gets loaded by doing
It should be something similiar to this when everything is all right.
reload kernel module
When there are problems with the GPU, maybe the kernel module isn't properly loaded.
You could recheck if the module has been properly loaded by doing
The kernel module could be loaded resp. reloaded with
Then, google the version number like
This example shows that the rendering of the desktop is performed by the graphical device of the Intel CPU, which is just like it's needed for running CUDA applications on your NVIDIA graphics card, if you don't have another one.
nvidia-cuda-toolkit
With the Debian package of the CUDA toolkit everything pretty much runs out of the box for Theano.
Just install it with
If you got a result like this you're ready to go with Theano on Debian, training computer vision classifiers or whatever you want to do with it.
I'll write more on for what Theano could be used, soon.
numpy.ndarray), which are broadly used in Scientific Python for the representation of numeric data.
It features a declarative Python based language with symbolic operations for the functional definition of mathematical expressions, which allows to create functions that compute values for them.
Internally the expressions are represented as directed graphs with nodes for variables and operations.
The internal compiler then optimizes those graphs for stability and speed and then generates high-performance native machine code to evaluate resp. compute these mathematical expressions2.
One of the main features of Theano is that it's capable to compute also on GPU processors (graphical processor unit), like on custom graphic cards (e.g. the developers are using a GeForce GTX Titan X for benchmarks).
Today's GPUs became very powerful parallel floating point devices which can be employed also for scientific computations instead of 3D video games3.
The acronym "GPGPU" (general purpose graphical processor unit) refers to special cards like NVIDIA's Tesla4, which could be used alike (more on that below).
Thus, Theano is a high-performance number cruncher with an own computing engine which could be used for large-scale scientific computations.
If you haven't came across Theano as a Pythonistic professional mathematician, it's also one of the most prevalent frameworks for implementing deep learning applications (training multi-layered, "deep" artificial neural networks, DNN) around5, and has been developed with a focus on machine learning from the ground up.
There are several higher level user interfaces build in the top of Theano (for DNN, Keras, Lasagne, Blocks, and others, or for Python probalistic programming, PyMC3).
I'll seek for some of them also becoming available in Debian, too.
helper scripts
Both binary packages ship three convenience scripts, theano-cache, theano-test, and theano-nose.
Instead of them being copied into /usr/bin, which would result into a binaries-have-conflict violation, the scripts are to be found in /usr/share/python-theano (python3-theano respectively), so that both module packages of Theano can be installed at the same time.
The scripts could be run directly from these folders, e.g. do $ python /usr/share/python-theano/theano-nose to achieve that.
If you're going to heavy use them, you could add the directory of the flavour you prefer (Python 2 or Python 3) to the $PATH environment variable manually by either typing e.g. $ export PATH=/usr/share/python-theano:$PATH on the prompt, or save that line into ~/.bashrc.
Manpages aren't available for these little helper scripts6, but you could always get info on what they do and which arguments they accept by invoking them with the -h (for theano-nose) resp. help flag (for theano-cache).
running the tests
On some occasions you might want to run the testsuite of the installed library, like to check over if everything runs fine on your GPU hardware.
There are two different ways to run the tests (anyway you need to have python ,3 -nose installed).
One is, you could launch the test suite by doing $ python -c 'import theano; theano.test() (or the same with python3 to test the other flavour), that's the same what the helper script theano-test does.
However, by doing it that way some particular tests might fail by raising errors also for the group of known failures.
Known failures are excluded from being errors if you run the tests by theano-nose, which is a wrapper around nosetests, so this might be always the better choice.
You can run this convenience script with the option --theano on the installed library, or from the source package root, which you could pull by $ sudo apt-get source theano (there you have also the option to use bin/theano-nose).
The script accept options for nosetests, so you might run it with -v to increase verbosity.
For the tests the configuration switch config.device must be set to cpu.
This will also include the GPU tests when a proper accessible device is detected, so that's a little misleading in the sense of it doesn't mean "run everything on the CPU".
You're on the safe side if you run it always like this: $ THEANO_FLAGS=device=cpu theano-nose, if you've set config.device to gpu in your ~/.theanorc.
Depending on the available hardware and the used BLAS implementation (see below) it could take quite a long time to run the whole test suite through, on the Core-i5 in my laptop that takes around an hour even excluded the GPU related tests (which perform pretty fast, though).
Theano features a couple of switches to manipulate the default configuration for optimization and compilation.
There is a rivalry between optimization and compilation costs against performance of the test suite, and it turned out the test suite performs a quicker with lesser graph optimization.
There are two different switches available to control config.optimizer, the fast_run toggles maximal optimization, while fast_compile runs only a minimal set of graph optimization features.
These settings are used by the general mode switches for config.mode, which is either FAST_RUN by default, or FAST_COMPILE.
The default mode FAST_RUN (optimizer=fast_run, linker=cvm) needs around 72 minutes on my lower mid-level machine (on un-optimized BLAS).
To set mode=FAST_COMPILE (optimizer=fast_compile, linker=py) brings some boost for the performance of the test suite because it runs the whole suite in 46 minutes.
The downside of that is that C code compilation is disabled in this mode by using the linker py, and also the GPU related tests are not included.
I've played around with using the optimizer fast_compile with some of the other linkers (c py and cvm, and their versions without garbage collection) as alternative to FAST_COMPILE with minimal optimization but also machine code compilation incl. GPU testing.
But to my experience, fast_compile without another than the linker py results in some new errors and failures of some tests on amd64, and this might the case also on other architectures, too.
By the way, another useful feature is DebugMode for config.mode, which verifies the correctness of all optimizations and compares the C to Python results.
If you want to have detailed info on the configuration settings of Theano, do $ python -c 'import theano; print theano.config' less, and check out the chapter config in the library documentation in the documentation.
cache maintenance
Theano isn't a JIT (just-in-time) compiler like Numba, which generates native machine code in the memory and executes it immediately, but it saves the generated native machine code into compiledirs.
The reason for doing it that way is quite practical like the docs explain, the persistent cache on disk makes it possible to avoid generating code for the same operation, and to avoid compiling again when different operations generate the same code.
The compiledirs by default are located within $(HOME)/.theano/.
After some time the folder becomes quite large, and might look something like this:
$ ls ~/.theano compiledir_Linux-4.5--amd64-x86_64-with-debian-stretch-sid--2.7.11+-64 compiledir_Linux-4.5--amd64-x86_64-with-debian-stretch-sid--2.7.12-64 compiledir_Linux-4.5--amd64-x86_64-with-debian-stretch-sid--2.7.12rc1-64 compiledir_Linux-4.5--amd64-x86_64-with-debian-stretch-sid--3.5.1+-64 compiledir_Linux-4.5--amd64-x86_64-with-debian-stretch-sid--3.5.2-64 compiledir_Linux-4.5--amd64-x86_64-with-debian-stretch-sid--3.5.2rc1-64
theano-cache comes in handy.
If you invoke it without any arguments the current cache location is put out like ~/.theano/compiledir_Linux-4.5--amd64-x86_64-with-debian-stretch-sid--2.7.12-64 (the script is run from /usr/share/python-theano).
So, the compiledirs for the old Python versions in this example (11+ and 12rc1) can be removed to free the space they occupy.
All compiledirs resp. cache directories meaning the whole cache could be erased by $ theano-cache basecompiledir purge, the effect is the same as by performing $ rm -rf ~/.theano.
You might want to do that e.g. if you're using different hardware, like when you got yourself another graphics card.
Or habitual from time to time when the compiledirs fill up so much that it slows down processing with the harddisk being very busy all the time, if you don't have an SSD drive available.
For example, the disk space of build chroots carrying (mainly) the tests completely compiled through on default Python 2 and Python 3 consumes around 1.3 GB (see here).
BLAS implementations
Theano needs a level 3 implementation of BLAS (Basic Linear Algebra Subprograms) for operations between vectors (one-dimensional mathematical objects) and matrices (two-dimensional objects) carried out on the CPU.
NumPy is already build on BLAS and pulls the standard implementation (libblas3, soure package: lapack), but Theano links directly to it instead of using NumPy as intermediate layer to reduce the computational overhead.
For this, Theano needs development headers and the binary packages pull libblas-dev by default, if any other development package of another BLAS implementation (like OpenBLAS or ATLAS) isn't already installed, or pulled with them (providing the virtual package libblas.so).
The linker flags could be manipulated directly through the configuration switch config.blas.ldflags, which is by default set to -L/usr/lib -lblas -lblas.
By the way, if you set it to an empty value, Theano falls back to using BLAS through NumPy, if you want to have that for some reason.
On Debian, there is a very convenient way to switch between BLAS implementations by the alternatives mechanism.
If you have several alternative implementations installed at the same time, you can switch from one to another easily by just doing:
$ sudo update-alternatives --config libblas.so There are 3 choices for the alternative libblas.so (providing /usr/lib/libblas.so). Selection Path Priority Status ------------------------------------------------------------ * 0 /usr/lib/openblas-base/libblas.so 40 auto mode 1 /usr/lib/atlas-base/atlas/libblas.so 35 manual mode 2 /usr/lib/libblas/libblas.so 10 manual mode 3 /usr/lib/openblas-base/libblas.so 40 manual mode Press <enter> to keep the current choice[*], or type selection number:
check_blas.py to check over how well a BLAS implementation performs with it, and if everything works right.
That script is located in the misc subfolder of the library, you could locate it by doing $ dpkg -L python-theano grep check_blas (or for the package python3-theano accordingly), and run it with the Python interpreter.
By default the scripts puts out a lot of info like a huge perfomance comparison reference table, the current setting of blas.ldflags, the compiledir, the setting of floatX, OS information, the GCC version, the current NumPy config towards BLAS, NumPy location and version, if Theano linked directly or has used the NumPy binding, and finally and most important, the execution time.
If just the execution time for quick perfomance comparisons is needed this script could be invoked with -q.
Theano on CUDA
The function compiler of Theano works with alternative backends to carry out the computations, like the ones for graphics cards.
Currently, there are two different backends for GPU processing available, one docks onto NVIDIA's CUDA (Compute Unified Device Architecture) technology7, and another one for libgpuarray, which is also developed by the Theano developers in parallel.
The libgpuarray library is an interesting alternative for Theano, it's a GPU tensor (multi-dimensional mathematical object) array written in C with Python bindings based on Cython, which has the advantage of running also on OpenCL8.
OpenCL, unlike CUDA9, is full free software, vendor neutral and overcomes the limitation of the CUDA toolkit being only available for amd64 and the ppc64el port (see here).
I've opened an ITP on libgpuarray and we'll see if and how this works out.
Another reason for it would be great to have it available is that it looks like CUDA currently runs into problems with GCC 610.
More on that, soon.
Here's a litle checklist for setting up your CUDA device so that you don't have to experience something like this:
$ THEANO_FLAGS=device=gpu,floatX=float32 python ./cat_dog_classifier.py WARNING (theano.sandbox.cuda): CUDA is installed, but device gpu is not available (error: Unable to get the number of gpus available: no CUDA-capable device is detected)
$ lspci grep -i nvidia 04:00.0 3D controller: NVIDIA Corporation GM108M [GeForce 940M] (rev a2)
rev ff appears at the end of the line that means the device is off meaning powered down.
This might be happening if you have a laptop with Optimus graphics hardware, and the related drivers have switched off the unoccupied device to safe energy11.
kernel module
Running CUDA applications requires the proprietary NVIDIA driver kernel module to be loaded into the kernel and working.
If you haven't already installed it for another purpose, the NVIDIA driver and the CUDA toolkit are both in the non-free section of the Debian archive, which is not enabled by default.
To get non-free packages you have to add non-free (and it's better to do so, also contrib) to your package source in /etc/apt/sources.list, which might then look like this:
deb http://httpredir.debian.org/debian/ testing main contrib non-free
$ apt-cache update to update the package lists, and there you go with the non-free packages.
The headers of the running kernel are needed to compile modules, you can get them together with the NVIDIA kernel module package by running:
$ sudo apt-get install linux-headers-$(uname -r) nvidia-kernel-dkms build-essential
$ lsmod grep nouveau.
If nothing gets returned, that's right.
If it's still in the kernel, just add blacklist nouveau to /etc/modprobe.d/blacklist.conf, and update the booting ramdisk with sudo update-initramfs -u afterwards.
Then reboot once more, this shouldn't be the case then anymore.
rebuild kernel module
To fix it when the module haven't been properly compiled for some reason you could trigger a rebuild of the NVIDIA kernel module with $ sudo dpkg-reconfigure nvidia-kernel-dkms.
When you're about to send your hardware in to repair because everything looks all right but the device just isn't working, that really could help (own experience).
After the rebuild of the module or modules (if you have a few kernel packages installed) has completed, you could recheck if the module really is available by running:
$ sudo modinfo nvidia-current filename: /lib/modules/4.4.0-1-amd64/updates/dkms/nvidia-current.ko alias: char-major-195-* version: 352.79 supported: external license: NVIDIA alias: pci:v000010DEd00000E00sv*sd*bc04sc80i00* alias: pci:v000010DEd*sv*sd*bc03sc02i00* alias: pci:v000010DEd*sv*sd*bc03sc00i00* depends: drm vermagic: 4.4.0-1-amd64 SMP mod_unload modversions parm: NVreg_Mobile:int
$ lsmod grep nvidia nvidia_uvm 73728 0 nvidia 8540160 1 nvidia_uvm drm 356352 7 i915,drm_kms_helper,nvidia
$ sudo nvidia-modprobe (that tool is from the package nvidia-modprobe).
unsupported graphics card
Be sure that you graphics cards is supported by the current driver kernel module.
If you have bought new hardware, that's quite possible to come out being a problem.
You can get the version of the current NVIDIA driver with:
$ cat /proc/driver/nvidia/version NVRM version: NVIDIA UNIX x86_64 Kernel Module 352.79 Wed Jan 13 16:17:53 PST 2016 GCC version: gcc version 5.3.1 20160528 (Debian 5.3.1-21)
nvidia 352.79, this should get you onto an official driver download page like this.
There, check for what's to be found under "Supported Products".
I you're stuck with that there are two options, to wait until the driver in Debian got updated, or replace it with the latest driver package from NVIDIA.
That's possible to do, but something more for experienced users.
occupied graphics card
The CUDA driver cannot work while the graphical interface is busy like by processing the graphical display of your X.Org server.
Which kernel driver actually is used to process the desktop could be examined by this command:12
$ grep '(II).*([0-9]):' /var/log/Xorg.0.log [ 37.700] (II) intel(0): Using Kernel Mode Setting driver: i915, version 1.6.0 20150522 [ 37.700] (II) intel(0): SNA compiled: xserver-xorg-video-intel 2:2.99.917-2 (Vincent Cheng <vcheng@debian.org>) ... [ 39.808] (II) intel(0): switch to mode 1920x1080@60.0 on eDP1 using pipe 0, position (0, 0), rotation normal, reflection none [ 39.810] (II) intel(0): Setting screen physical size to 508 x 285 [ 67.576] (II) intel(0): EDID vendor "CMN", prod id 5941 [ 67.576] (II) intel(0): Printing DDC gathered Modelines: [ 67.576] (II) intel(0): Modeline "1920x1080"x0.0 152.84 1920 1968 2000 2250 1080 1083 1088 1132 -hsync -vsync (67.9 kHz eP)
apt-get, and you're ready to go, the CUDA backend is the default one.
Pycuda is also a suggested dependency of the binary packages, it could be pulled together with the CUDA toolkit.
The up-to-date CUDA release 7.5 is of course available, with that you have Maxwell architecture support so that you can run Theano on e.g. a GeForce GTX Titan X with 6,2 TFLOPS on single precision13 at an affordable price.
CUDA 814 is around the corner with support for the new Pascal architecture15.
Like the GeForce GTX 1080 high-end gaming graphics card already has 8,23 TFLOPS16.
When it comes to professional GPGPU hardware like the Tesla P100 there is much more computational power available, scalable by multiplication of cores resp. cards up to genuine little supercomputers which fit on a desk, like the DGX-117.
Theano can use multiple GPUs for calculations to work with highly scaled hardware, I'll write another blog post on this issue.
Theano on the GPU
It's not difficult to run Theano on the GPU.
Only single precision floating point numbers (float32) are supported on the GPU, but that is sufficient for deep learning applications.
Theano uses double precision floats (float64) by default, so you have to set the configuration variable config.floatX to float32, like written on above, either with the THEANO_FLAGS environment variable or better in your .theanorc file, if you're going to use the GPU a lot.
Switching to the GPU actually happens with the config.device configuration variable, which must be set to either gpu or gpu0, gpu1 etc., to choose a particular one if multiple devices are available.
Here's is a little test script check1.py, it's taken from the docs and slightly altered.
You can run that script either with python or python3 (there was a single test failure on the Python 3 package, so the Python 2 library might be a little more stable currently).
For comparison, here's an example on how it perfoms on my hardware, one time on the CPU, one more time on the GPU:
$ THEANO_FLAGS=floatX=float32 python ./check1.py [Elemwise exp,no_inplace (<TensorType(float32, vector)>)] Looping 1000 times took 4.481719 seconds Result is [ 1.23178029 1.61879337 1.52278066 ..., 2.20771813 2.29967761 1.62323284] Used the cpu $ THEANO_FLAGS=floatX=float32,device=gpu python ./check1.py Using gpu device 0: GeForce 940M (CNMeM is disabled, cuDNN not available) [GpuElemwise exp,no_inplace (<CudaNdarrayType(float32, vector)>), HostFromGpu(GpuElemwise exp,no_inplace .0)] Looping 1000 times took 1.164906 seconds Result is [ 1.23178029 1.61879349 1.52278066 ..., 2.20771813 2.29967761 1.62323296] Used the gpu
-
Some ports are disabled because they are currently not supported by Theano.
There are NotImplementedErrors and other errors in the tests on the numpy.ndarray object being not aligned.
The developers commented on that, see here.
And on some ports the build flags
-m32resp.-m64of Theano aren't supported by g++, the build flags can't be manipulated easily. - Theano Development Team: "Theano: a Python framework for fast computation of mathematical expressions"
- Marc Couture: "Today's high-powered GPUs: strong for graphics and for maths". In: RTC magazine June 2015, pp. 22 25
- Ogier Maitre: "Understanding NVIDIA GPGPU hardware". In: Tsutsui/Collet (eds.): Massively parallel evolutionary computation on GPGPUs. Berlin, Heidelberg: Springer 2013, pp. 15-34
- Geoffrey French: "Deep learing tutorial: advanved techniques". PyData London 2016 presentation
-
Like the description of the Lintian tag binary-without-manpage says, that's not needed for them being in
/usr/share. - Tom. R. Halfhill: "Parallel processing with CUDA: Nvidia's high-performance computing platform uses massive multithreading". In: Microprocessor Report January 28, 2008
- Faber et.al: "Parallelwelten: GPU-Programmierung mit OpenCL". In: C't 26/2014, pp. 160-165
- For comparison, see: Valentine Sinitsyn: "Feel the taste of GPU programming". In: Linux Voice February 2015, pp. 106-109
- https://lists.debian.org/debian-devel/2016/07/msg00004.html
- If Optimus (hybrid) graphics hardware is present (like commonly today on PC laptops), Debian launches the X-server on the graphics processing unit of the CPU, which is ideal for CUDA. The problem with Optimus actually is the graphics processing on the dedicated GPU. If you are using Bumblebee, the Python interpreter which you want to run Theano on has be to be started with the launcher primusrun, because Bumblebee powers the GPU down with the tool bbswitch every time it isn't used, and I think also the kernel module of the driver is dynamically loaded.
- Thorsten Leemhuis: "Treiberreviere. Probleme mit Grafiktreibern f r Linux l sen": In: C't Nr.2/2013, pp. 156-161
- Martin Fischer: "4K-Rakete: Die schnellste Single-GPU-Grafikkarte der Welt". In C't 13/2015, pp. 60-61
- http://www.heise.de/developer/meldung/Nvidia-CUDA-8-bringt-Optimierungen-fuer-die-Pascal-Architektur-3164254.html
- Martin Fischer: "All In: Nvidia enth llt die GPU-Architektur 'Pascal'". In: C't 9/2016, pp. 30-31
- Martin Fischer: "Turbo-Pascal: High-End-Grafikkarte f r Spieler: GeForce GTX 1080". In: C't 13/2016, pp. 100-103
- http://www.golem.de/news/dgx-1-nvidias-supercomputerchen-mit-8x-tesla-p100-1604-120155.html
 Long over due post
It s been a long time I haven t written here. And lots of things happened in the OpenStack planet. As a full time employee with the mission to package OpenStack in Debian, it feels like it is kind of my duty to tell everyone about what s going on.
Liberty is out, uploaded to Debian
Since my last post, OpenStack Liberty, the 12th release of OpenStack, was released. In late August, Debian was the first platform which included Liberty, as I proudly outran both RDO and Canonical. So I was the first to make the announcement that Liberty passed most of the Tempest tests with the beta 3 release of Liberty (the Beta 3 is always kind of the first pre-release, as this is when feature freeze happens). Though I never made the announcement that Liberty final was uploaded to Debian, it was done just a single day after the official release.
Before the release, all of Liberty was living in Debian Experimental. Following the upload of the final packages in Experimental, I uploaded all of it to Sid. This represented 102 packages, so it took me about 3 days to do it all.
Tokyo summit
I had the pleasure to be in Tokyo for the Mitaka summit. I was very pleased with the cross-project sessions during the first day. Lots of these sessions were very interesting for me. In fact, I wish I could have attended them all, but of course, I can t split myself in 3 to follow all of the 3 tracks.
Then there was the 2 sessions about Debian packaging on upstream OpenStack infra. The goal is to setup the OpenStack upstream infrastructure to allow packaging using Gerrit, and gating each git commit using the usual tools: building the package and checking there s no FTBFS, running checks like lintian, piuparts and such. I knew already the overview of what was needed to make it happen. What I didn t know was the implementation details, which I hoped we could figure out during the 1:30 slot. Unfortunately, this didn t happen as I expected, and we discussed more general things than I wished. I was told that just reading the docs from the infra team was enough, but in reality, it was not. What currently needs to happen is building a Debian based image, using disk-image-builder, which would include the usual tools to build packages: git-buildpackage, sbuild, and so on. I m still stuck at this stage, which would be trivial if I knew a bit more about how upstream infra works, since I already know how to setup all of that on a local machine.
I ve been told by Monty Tailor that he would help. Though he s always a very busy man, and to date, he still didn t find enough time to give me a hand. Nobody replied to my request for help in the openstack-dev list either. Hopefully, with a bit of insistence, someone will help.
Keystone migration to Testing (aka: Debian Stretch) blocked by python-repoze.who
Absolutely all of OpenStack Liberty, as of today, has migrated to Stretch. All? No. Keystone is blocked by a chain of dependency. Keystone depends on python-pysaml2, itself blocked by python-repoze.who. The later, I upgraded it to version 2.2. Though python-repoze.what depends on version <= 1.9, which is blocking the migration. Since python-repoze.who-plugins, python-repoze.what and python-repoze.what-plugins aren t used by any package anymore, I asked for them to be removed from Debian (see #805407). Until this request is processed by the FTP masters, Keystone, which is the most important piece of OpenStack (it does the authentication) will be blocked for migration to Stretch.
New OpenStack server packages available
On my presentation at Debconf 15, I quickly introduced new services which were released upstream. I have since packaged them all:
Long over due post
It s been a long time I haven t written here. And lots of things happened in the OpenStack planet. As a full time employee with the mission to package OpenStack in Debian, it feels like it is kind of my duty to tell everyone about what s going on.
Liberty is out, uploaded to Debian
Since my last post, OpenStack Liberty, the 12th release of OpenStack, was released. In late August, Debian was the first platform which included Liberty, as I proudly outran both RDO and Canonical. So I was the first to make the announcement that Liberty passed most of the Tempest tests with the beta 3 release of Liberty (the Beta 3 is always kind of the first pre-release, as this is when feature freeze happens). Though I never made the announcement that Liberty final was uploaded to Debian, it was done just a single day after the official release.
Before the release, all of Liberty was living in Debian Experimental. Following the upload of the final packages in Experimental, I uploaded all of it to Sid. This represented 102 packages, so it took me about 3 days to do it all.
Tokyo summit
I had the pleasure to be in Tokyo for the Mitaka summit. I was very pleased with the cross-project sessions during the first day. Lots of these sessions were very interesting for me. In fact, I wish I could have attended them all, but of course, I can t split myself in 3 to follow all of the 3 tracks.
Then there was the 2 sessions about Debian packaging on upstream OpenStack infra. The goal is to setup the OpenStack upstream infrastructure to allow packaging using Gerrit, and gating each git commit using the usual tools: building the package and checking there s no FTBFS, running checks like lintian, piuparts and such. I knew already the overview of what was needed to make it happen. What I didn t know was the implementation details, which I hoped we could figure out during the 1:30 slot. Unfortunately, this didn t happen as I expected, and we discussed more general things than I wished. I was told that just reading the docs from the infra team was enough, but in reality, it was not. What currently needs to happen is building a Debian based image, using disk-image-builder, which would include the usual tools to build packages: git-buildpackage, sbuild, and so on. I m still stuck at this stage, which would be trivial if I knew a bit more about how upstream infra works, since I already know how to setup all of that on a local machine.
I ve been told by Monty Tailor that he would help. Though he s always a very busy man, and to date, he still didn t find enough time to give me a hand. Nobody replied to my request for help in the openstack-dev list either. Hopefully, with a bit of insistence, someone will help.
Keystone migration to Testing (aka: Debian Stretch) blocked by python-repoze.who
Absolutely all of OpenStack Liberty, as of today, has migrated to Stretch. All? No. Keystone is blocked by a chain of dependency. Keystone depends on python-pysaml2, itself blocked by python-repoze.who. The later, I upgraded it to version 2.2. Though python-repoze.what depends on version <= 1.9, which is blocking the migration. Since python-repoze.who-plugins, python-repoze.what and python-repoze.what-plugins aren t used by any package anymore, I asked for them to be removed from Debian (see #805407). Until this request is processed by the FTP masters, Keystone, which is the most important piece of OpenStack (it does the authentication) will be blocked for migration to Stretch.
New OpenStack server packages available
On my presentation at Debconf 15, I quickly introduced new services which were released upstream. I have since packaged them all:
 The
The  What happened about the
What happened about the  Jebediah boarded the airplane. It was a Bombardier CRJ900 with two
turbofan jet engines. Run by SPARK, a subset of Ada. He sat down
in his assigned seat and listened to the purser inform him that he
was free to use his phone door-to-door on all Delta Connection
flights. As long as the Airplane Mode was switched on.
Jebediah knew that this was why Delta owned 49% of Virgin Atlantic.
On the plane ride, a woman in too much makeup asked Jebediah to
get the man next to him so she could borrow his copy of the
Economist. The man said she could keep it and that it was old.
He had stubby little fingers. She was foreign.
At Terminal 2, they passed by Kids on the Fly, an exhibit of the
Chicago Children's Museum at Chicago O'Hare International Airport.
A play area. Jebediah thought of Dennis.
The Blue Line of the Chicago Transit Authority was disrupted by
weekend construction, so they had to take a small detour through
Wicker Park. Wicker Park is a neighborhood. In Chicago. Jebediah
looked at Glazed & Infused Doughnuts. He wondered if they made
doughnuts there. Because of the meeting, he knocked someone off
a Divvy bike and pedaled it to the Loop.
The Berghoff was opened in 1898 by Herman Joseph Berghoff.
Once he got to the Berghoff, he got a table for seven on the west
wall. He eyed the electrical outlet and groaned. He had brought
3 cigarette lighter adapters with him, but nothing to plug into
an AC outlet. How would he charge his device? An older gentleman
came in. And greeted him.
Hello, I'm Detective Chief Inspector Detweiler. Did you bring
the evidence? Said the man.
Jebediah coughed and said that he had to go downstairs. He went
downstairs and looked at the doors. He breathed a sigh of relief.
Seeing the word washroom in print reminded him of his home state
of Canada. Back at the table he opened a bag, glared angrily
at a cigarette lighter adapter, and pulled out a Palm m125.
Running Palm OS 4.0. He noticed a third person at the table.
It was the ghost of Bob Ross.
, said the ghost of Bob Ross. It was
good for him to communicate telepathically with Sarah Palin.
This has eight megabytes of RAM, Jebediah informed the newcomer.
Bob Ross's ghost right-clicked on his face and rated him one star.
Jebediah looked angrily at the AC outlet and fidgeted with two
of his cigarette lighter adapters.
DCI Detweiler said, I had a Handspring Visor Deluxe, and pulled
out a Samsung Galaxy Tab 3 8.0 eight-inch Android-based tablet
computer running the Android 4.2.2 Jelly Bean operating system
by Google. This also has eight megabytes of RAM, he continued.
As you requested, I brought the video of your nemesis at the
Robie House.
Jebediah stared at the tablet. He could see a compressed video
file, compressed with NetBSD compression and GNU encryption.
It was on the tablet. Some bridges you just don't cross,
he hissed.
Meanwhile, in Gloucestershire, someone who looked suspiciously
like Bobby Rainsbury opened up a MacBook Air and typed in a
three-digit passcode. Across the street a wall safe slid
out of the wall. And dropped onto someone's head. She
closed the laptop. And went to Dumfries.
Not far from the fallen safe, a group of men held a discussion.
FBI: Why are we here on this junket?
CIA: Where are we?
DIA: We're here.
JIA: This is confusing.
NSA: I have to get back to that place in Germany where I don't work.
ATF: We're talking about giant robots here, people.
EPA: Huh?
Part 2
AUD:USD 1.0645
donuts:dozen 12
Gold $1318.60
Giant robot spiders fought each other in a supermarket parking
lot.
Detective Seabiscuit sucked on a throat lozenge. Who are you
again? he asked the toll-booth operator.
I said my name is Rogery Sterling, replied the toll-booth
operator.
Rajry what?
I said my name is Rogery Sterling, replied the toll-booth
operator. Again.
Where am I?
Look, I'm telling you that that murder you're investigating
was caused by software bugs in the software.
Are we on a boat?
Look at the diagram. This agency paid money to introduce,
quite deliberately, weaknesses in the security of this library,
through this company here, and this company here.
Library, oh no. I have overdue fees.
And they're running a PR campaign to increase use of this
library. Saying that the competing options are inferior.
But don't worry, they're trying to undermine those too.
Detective Seabiscuit wasn't listening. He had just remembered
that he needed to stop by the Robie House.
Jebediah boarded the airplane. It was a Bombardier CRJ900 with two
turbofan jet engines. Run by SPARK, a subset of Ada. He sat down
in his assigned seat and listened to the purser inform him that he
was free to use his phone door-to-door on all Delta Connection
flights. As long as the Airplane Mode was switched on.
Jebediah knew that this was why Delta owned 49% of Virgin Atlantic.
On the plane ride, a woman in too much makeup asked Jebediah to
get the man next to him so she could borrow his copy of the
Economist. The man said she could keep it and that it was old.
He had stubby little fingers. She was foreign.
At Terminal 2, they passed by Kids on the Fly, an exhibit of the
Chicago Children's Museum at Chicago O'Hare International Airport.
A play area. Jebediah thought of Dennis.
The Blue Line of the Chicago Transit Authority was disrupted by
weekend construction, so they had to take a small detour through
Wicker Park. Wicker Park is a neighborhood. In Chicago. Jebediah
looked at Glazed & Infused Doughnuts. He wondered if they made
doughnuts there. Because of the meeting, he knocked someone off
a Divvy bike and pedaled it to the Loop.
The Berghoff was opened in 1898 by Herman Joseph Berghoff.
Once he got to the Berghoff, he got a table for seven on the west
wall. He eyed the electrical outlet and groaned. He had brought
3 cigarette lighter adapters with him, but nothing to plug into
an AC outlet. How would he charge his device? An older gentleman
came in. And greeted him.
Hello, I'm Detective Chief Inspector Detweiler. Did you bring
the evidence? Said the man.
Jebediah coughed and said that he had to go downstairs. He went
downstairs and looked at the doors. He breathed a sigh of relief.
Seeing the word washroom in print reminded him of his home state
of Canada. Back at the table he opened a bag, glared angrily
at a cigarette lighter adapter, and pulled out a Palm m125.
Running Palm OS 4.0. He noticed a third person at the table.
It was the ghost of Bob Ross.
, said the ghost of Bob Ross. It was
good for him to communicate telepathically with Sarah Palin.
This has eight megabytes of RAM, Jebediah informed the newcomer.
Bob Ross's ghost right-clicked on his face and rated him one star.
Jebediah looked angrily at the AC outlet and fidgeted with two
of his cigarette lighter adapters.
DCI Detweiler said, I had a Handspring Visor Deluxe, and pulled
out a Samsung Galaxy Tab 3 8.0 eight-inch Android-based tablet
computer running the Android 4.2.2 Jelly Bean operating system
by Google. This also has eight megabytes of RAM, he continued.
As you requested, I brought the video of your nemesis at the
Robie House.
Jebediah stared at the tablet. He could see a compressed video
file, compressed with NetBSD compression and GNU encryption.
It was on the tablet. Some bridges you just don't cross,
he hissed.
Meanwhile, in Gloucestershire, someone who looked suspiciously
like Bobby Rainsbury opened up a MacBook Air and typed in a
three-digit passcode. Across the street a wall safe slid
out of the wall. And dropped onto someone's head. She
closed the laptop. And went to Dumfries.
Not far from the fallen safe, a group of men held a discussion.
FBI: Why are we here on this junket?
CIA: Where are we?
DIA: We're here.
JIA: This is confusing.
NSA: I have to get back to that place in Germany where I don't work.
ATF: We're talking about giant robots here, people.
EPA: Huh?
Part 2
AUD:USD 1.0645
donuts:dozen 12
Gold $1318.60
Giant robot spiders fought each other in a supermarket parking
lot.
Detective Seabiscuit sucked on a throat lozenge. Who are you
again? he asked the toll-booth operator.
I said my name is Rogery Sterling, replied the toll-booth
operator.
Rajry what?
I said my name is Rogery Sterling, replied the toll-booth
operator. Again.
Where am I?
Look, I'm telling you that that murder you're investigating
was caused by software bugs in the software.
Are we on a boat?
Look at the diagram. This agency paid money to introduce,
quite deliberately, weaknesses in the security of this library,
through this company here, and this company here.
Library, oh no. I have overdue fees.
And they're running a PR campaign to increase use of this
library. Saying that the competing options are inferior.
But don't worry, they're trying to undermine those too.
Detective Seabiscuit wasn't listening. He had just remembered
that he needed to stop by the Robie House.
 January
January
 Entered monthly 10km races in Regent's Park, reducing my time from 55:07 in January 4th to 43:28 on December 1st.
February
Entered monthly 10km races in Regent's Park, reducing my time from 55:07 in January 4th to 43:28 on December 1st.
February
 Entered the
Entered the  Had my lute returned after it was damaged.
April
Had my lute returned after it was damaged.
April
 Had a time-trial bike built and raced my
Had a time-trial bike built and raced my  More biking, including a long ride with my brother. Also performed on the viola da gamba in Bach's St John Passion with
More biking, including a long ride with my brother. Also performed on the viola da gamba in Bach's St John Passion with  Two big concerts: Monn's Cello concerto in G minor with the
Two big concerts: Monn's Cello concerto in G minor with the  Amongst more triathlon preperation, I performed in a
Amongst more triathlon preperation, I performed in a  Raced my
Raced my  Whilst procrastinating about writing some letters, I
Whilst procrastinating about writing some letters, I  Started cooking a little more adventurously.
November
Started cooking a little more adventurously.
November
 Performed Geminiani's arrangement of Corelli's La Folia in the Fitzwilliam Museum with Le Petit Orchestre.
December
Performed Geminiani's arrangement of Corelli's La Folia in the Fitzwilliam Museum with Le Petit Orchestre.
December
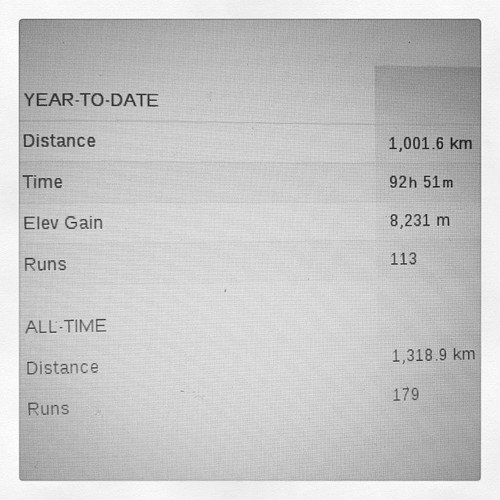 Ramped up my running volume so I could go over 1000km for the year. (
Ramped up my running volume so I could go over 1000km for the year. ( A nice set of recent posts have done a great job detailing the remaining ways that a root user can get at kernel memory. Part of this is driven by the ideas behind UEFI Secure Boot, but they come from the same goal: making sure that the root user cannot directly subvert the running kernel. My perspective on this is toward making sure that an attacker who has gained access and then gained root privileges can t continue to elevate their access and install invisible kernel rootkits.
An outline for possible attack vectors is spelled out by Matthew Gerrett s continuing
A nice set of recent posts have done a great job detailing the remaining ways that a root user can get at kernel memory. Part of this is driven by the ideas behind UEFI Secure Boot, but they come from the same goal: making sure that the root user cannot directly subvert the running kernel. My perspective on this is toward making sure that an attacker who has gained access and then gained root privileges can t continue to elevate their access and install invisible kernel rootkits.
An outline for possible attack vectors is spelled out by Matthew Gerrett s continuing 
 Since becoming interested in triathlon in October of last year, my goal in 2013 was not to just finish a "70.3" (or "Half-Ironman"), but to complete one in under 5 hours.
At the time, each discipline was woefully inadequate; I had not swum in over a decade, my cycling was average and I had only begun running again after years away from exercise.
The somewhat arbitrary target time would dictate my training. For example, the high proportion of time spent on the bike combined with the injury-sensitive nature of running meant that cycling would have a highest return on investment of the three disciplines. Despite that, I would need to take the run seriously but carefully - I decided to enter a series of monthly 10K races where I could steadily reduce my times over the year.
Races themselves formed a crucial part of my preparation and a carefully balanced race calendar was surprisingly important, balancing upcoming milestones that would provide an achievable goal as well as uncovering weaknesses in enough time so they could be worked on.
Whilst I did post about
Since becoming interested in triathlon in October of last year, my goal in 2013 was not to just finish a "70.3" (or "Half-Ironman"), but to complete one in under 5 hours.
At the time, each discipline was woefully inadequate; I had not swum in over a decade, my cycling was average and I had only begun running again after years away from exercise.
The somewhat arbitrary target time would dictate my training. For example, the high proportion of time spent on the bike combined with the injury-sensitive nature of running meant that cycling would have a highest return on investment of the three disciplines. Despite that, I would need to take the run seriously but carefully - I decided to enter a series of monthly 10K races where I could steadily reduce my times over the year.
Races themselves formed a crucial part of my preparation and a carefully balanced race calendar was surprisingly important, balancing upcoming milestones that would provide an achievable goal as well as uncovering weaknesses in enough time so they could be worked on.
Whilst I did post about 

 (
(


 On Monday I took part in my first triathlon, a "sprint" distance race organised by
On Monday I took part in my first triathlon, a "sprint" distance race organised by  (
(