Thomas Koch: Minimal overhead VMs with Nix and MicroVM

Posted on March 17, 2024
Joachim Breitner wrote about a Convenient sandboxed development environment and thus reminded me to blog about MicroVM. I ve toyed around with it a little but not yet seriously used it as I m currently not coding.
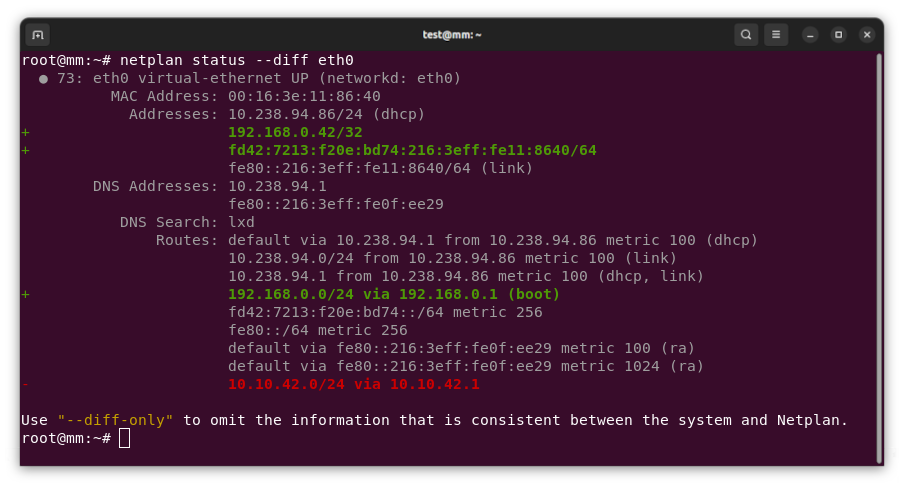
MicroVM is a nix based project to configure and run minimal VMs. It can mount and thus reuse the hosts nix store inside the VM and thus has a very small disk footprint. I use MicroVM on a debian system using the nix package manager.
The MicroVM author uses the project to host production services. Otherwise I consider it also a nice way to learn about NixOS after having started with the nix package manager and before making the big step to NixOS as my main system.
The guests root filesystem is a tmpdir, so one must explicitly define folders that should be mounted from the host and thus be persistent across VM reboots.
I defined the VM as a nix flake since this is how I started from the MicroVM projects example:
description = "Haskell dev MicroVM";
inputs.impermanence.url = "github:nix-community/impermanence";
inputs.microvm.url = "github:astro/microvm.nix";
inputs.microvm.inputs.nixpkgs.follows = "nixpkgs";
outputs = self, impermanence, microvm, nixpkgs :
let
persistencePath = "/persistent";
system = "x86_64-linux";
user = "thk";
vmname = "haskell";
nixosConfiguration = nixpkgs.lib.nixosSystem
inherit system;
modules = [
microvm.nixosModules.microvm
impermanence.nixosModules.impermanence
( pkgs, ... :
environment.persistence.$ persistencePath =
hideMounts = true;
users.$ user =
directories = [
"git" ".stack"
];
;
;
environment.sessionVariables =
TERM = "screen-256color";
;
environment.systemPackages = with pkgs; [
ghc
git
(haskell-language-server.override supportedGhcVersions = [ "94" ]; )
htop
stack
tmux
tree
vcsh
zsh
];
fileSystems.$ persistencePath .neededForBoot = nixpkgs.lib.mkForce true;
microvm =
forwardPorts = [
from = "host"; host.port = 2222; guest.port = 22;
from = "guest"; host.port = 5432; guest.port = 5432; # postgresql
];
hypervisor = "qemu";
interfaces = [
type = "user"; id = "usernet"; mac = "00:00:00:00:00:02";
];
mem = 4096;
shares = [
# use "virtiofs" for MicroVMs that are started by systemd
proto = "9p";
tag = "ro-store";
# a host's /nix/store will be picked up so that no
# squashfs/erofs will be built for it.
source = "/nix/store";
mountPoint = "/nix/.ro-store";
proto = "virtiofs";
tag = "persistent";
source = "~/.local/share/microvm/vms/$ vmname /persistent";
mountPoint = persistencePath;
socket = "/run/user/1000/microvm-$ vmname -persistent";
];
socket = "/run/user/1000/microvm-control.socket";
vcpu = 3;
volumes = [];
writableStoreOverlay = "/nix/.rwstore";
;
networking.hostName = vmname;
nix.enable = true;
nix.nixPath = ["nixpkgs=$ builtins.storePath <nixpkgs> "];
nix.settings =
extra-experimental-features = ["nix-command" "flakes"];
trusted-users = [user];
;
security.sudo =
enable = true;
wheelNeedsPassword = false;
;
services.getty.autologinUser = user;
services.openssh =
enable = true;
;
system.stateVersion = "24.11";
systemd.services.loadnixdb =
description = "import hosts nix database";
path = [pkgs.nix];
wantedBy = ["multi-user.target"];
requires = ["nix-daemon.service"];
script = "cat $ persistencePath /nix-store-db-dump nix-store --load-db";
;
time.timeZone = nixpkgs.lib.mkDefault "Europe/Berlin";
users.users.$ user =
extraGroups = [ "wheel" "video" ];
group = "user";
isNormalUser = true;
openssh.authorizedKeys.keys = [
"ssh-rsa REDACTED"
];
password = "";
;
users.users.root.password = "";
users.groups.user = ;
)
];
;
in
packages.$ system .default = nixosConfiguration.config.microvm.declaredRunner;
;
[Unit]
Description=MicroVM for Haskell development
Requires=microvm-virtiofsd-persistent@.service
After=microvm-virtiofsd-persistent@.service
AssertFileNotEmpty=%h/.local/share/microvm/vms/%i/flake/flake.nix
[Service]
Type=forking
ExecStartPre=/usr/bin/sh -c "[ /nix/var/nix/db/db.sqlite -ot %h/.local/share/microvm/nix-store-db-dump ] nix-store --dump-db >%h/.local/share/microvm/nix-store-db-dump"
ExecStartPre=ln -f -t %h/.local/share/microvm/vms/%i/persistent/ %h/.local/share/microvm/nix-store-db-dump
ExecStartPre=-%h/.local/state/nix/profile/bin/tmux new -s microvm -d
ExecStart=%h/.local/state/nix/profile/bin/tmux new-window -t microvm: -n "%i" "exec %h/.local/state/nix/profile/bin/nix run --impure %h/.local/share/microvm/vms/%i/flake"
[Unit]
Description=serve host persistent folder for dev VM
AssertPathIsDirectory=%h/.local/share/microvm/vms/%i/persistent
[Service]
ExecStart=%h/.local/state/nix/profile/bin/virtiofsd \
--socket-path=$ XDG_RUNTIME_DIR /microvm-%i-persistent \
--shared-dir=%h/.local/share/microvm/vms/%i/persistent \
--gid-map :995:%G:1: \
--uid-map :1000:%U:1:












 Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing
Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing  My Debian contributions this month were all
My Debian contributions this month were all
 One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time
One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a
I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a  Recently, I got a new laptop and had to set it up so I could start using it. But
I wasn't really in the mood to go through the same old steps which I had
explained in this
Recently, I got a new laptop and had to set it up so I could start using it. But
I wasn't really in the mood to go through the same old steps which I had
explained in this 







 After more than one a year, a new minor FAI version is available, but
it includes some interesting new features.
Here a the items from the NEWS file:
fai (6.2) unstable; urgency=low
After more than one a year, a new minor FAI version is available, but
it includes some interesting new features.
Here a the items from the NEWS file:
fai (6.2) unstable; urgency=low
 This year was hard from a personal and work point of view, which impacted the amount of Free Software bits I ended up doing - even when I had the time I often wasn t in the right head space to make progress on things. However writing this annual recap up has been a useful exercise, as I achieved more than I realised. For previous years see
This year was hard from a personal and work point of view, which impacted the amount of Free Software bits I ended up doing - even when I had the time I often wasn t in the right head space to make progress on things. However writing this annual recap up has been a useful exercise, as I achieved more than I realised. For previous years see